第17章-3-集合
概述
集合是Java中重要的内容,是Java数据结构的实现
针对应用中数据处理常见的高频操作进行封装,操作简单
可分为两个系列:Collection系列和Map系列
这两个系列的很多类,都有着相应的存储结构,常见存储结构有
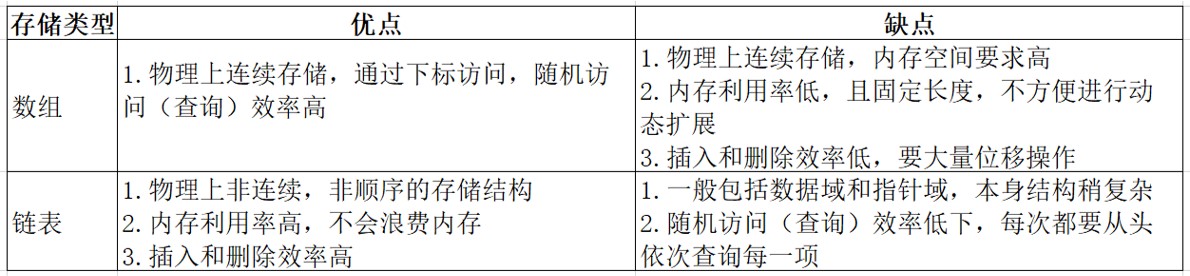
Collection系列
提问:数组使用过程中,有没有什么痛点?
答:容量固定,不可扩充容量。一般的业务中,都有连续存储相同系列数据的需要,但数量是动态的,或是不确定的
概述
Collection是Java中提供的一种容器,可以用来存放多个数据
Collection中数据的数据类型只能是引用数据类型,数据个数可动态扩容
应用场景:
现在想要一个存放班级学员的容器,人来来去去的,人数是不确定的,这个人员需要一个动态的容器存储,如下图
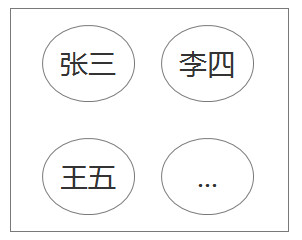
一个订单类,不同的人下的订单,里面的产品数量也不相同,这个订单的产品需要一个动态的容器存储
...
与数组对比
- 数组是固定大小,Collection集合则是动态大小,自动扩容
- 数组支持基本数据类型和引用数据类型,Collection集合则只支持引用数据类型
在实际开发过程中,更多的使用Collection集合类,并结合Lambda一起使用
Collection集合中的所有类和接口都派生于Collection接口
主要分为可重复集合、不可重复集合两类
Collection关系图谱
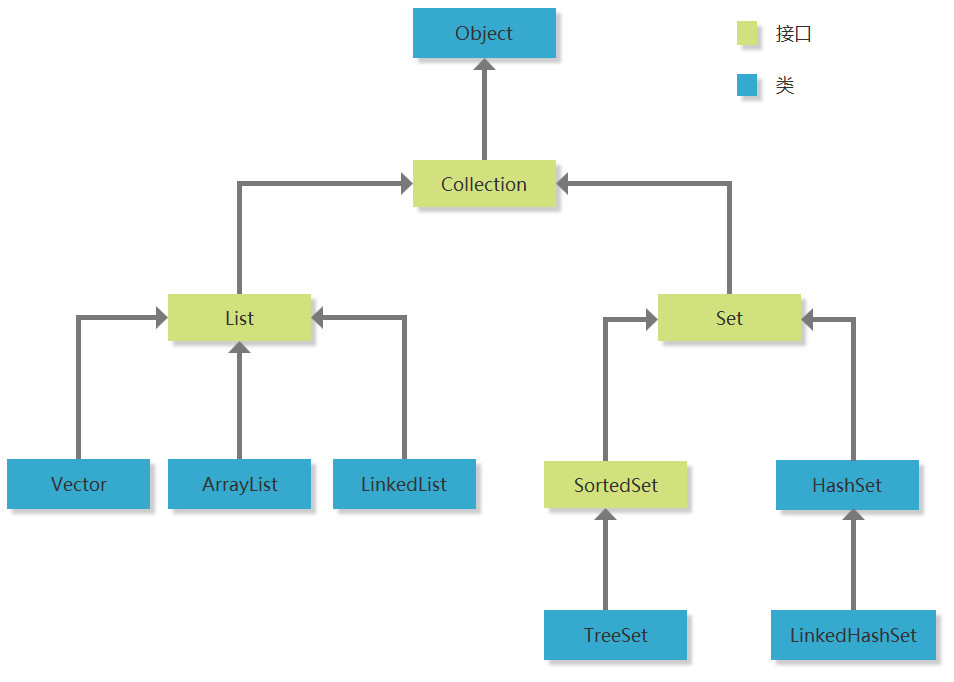
常用Collection类和接口
- Collection接口,集合类的父接口,定义了一系列通用方法
- List接口,可重复集合的父接口,扩展了一系列方法,可通过索引精确访问元素,数据可重复
- Vector类,早期旧版集合类,效率较低,但线程安全,现使用ArrayList可完全替代
- ArrayList类,使用数组存储元素的集合类,能自动扩容;是最常用的集合类
- LinkedList类,使用链表存储元素的集合类,能自动扩容
- Set接口,不可重复集合父接口
- SortedSet接口,提供一个有序的不可重复的接口
- TreeSet类,SortedSet的具体实现类,底层数据结构是红黑树(一个自平衡的二叉树)
- HashSet类,基于HashMap实现的,通过哈希算法决定元素存储位置,存取速度快,但是无序的
- LinkedHashSet类,继承于HashSet,具备HashSet特点,另外通过一个链表维护数据的顺序,可以是有序的,面对大量数据的遍历性能要好
- SortedSet接口,提供一个有序的不可重复的接口
- List接口,可重复集合的父接口,扩展了一系列方法,可通过索引精确访问元素,数据可重复
List
概述
- 是实际开发中常用的Collection集合类
- 常用的子类有ArrayList、LinkedList
- ArrayList特点
- 使用数组存储,有序,可重复
- 只支持引用数据类型
- 初始容量(initialCapacity)为10
- 超过长度后,后续每次按原有容量的50%进行扩容;由于扩容是通过重新申请一个新的数组,然后将旧数组内容拷贝到新数组完成,所以建议如果能预估其容量,尽量一步到位参考最大容量设置初始容量值
- 线程不安全
- 提供了很多便利的操作方法
- LinkedList特点
- 使用双向链表存储,有序,可重复
- 只支持引用数组类型
- 没有初始容量的需要
- 没有扩容的机制,只要内存足够,就能存储更多的元素
- 线程不安全
- 提供了很多便利的操作方法
- 建议:如果是查询多,插入、删除少,使用ArrayList;如果是插入、删除多,查询少,使用LinkedList
List常用方法
- size方法,集合长度
- add方法,往集合中添加一个元素
- get方法,获取指定下标的元素,下标从0开始
- remove方法,删除指定下标的数据,也可以删除某个指定元素
- set方法,修改指定位置的元素
- contains方法,是否包含某个元素
- isEmpty方法,集合是否为空,即不包含一个元素
- ...
注意:后面示例主要使用ArrayList,如果需要,都可以使用LinkedList进行替换
ArrayList
源码解析
注意:模拟的是JDK1.7的代码,其他版本的略有不同
具有两个私有属性,分别是数组和大小
/**
* 模拟ArrayList集合
*/
public class ArrayList<E> {
/**
* 定义一个数组,用于保存集合中的元素
*/
private Object[] elementData;
/**
* 定义一个变量,用于保存实际添加元素的个数
*/
private int size;
}具备两个构造方法
/**
* 模拟ArrayList集合
*/
public class ArrayList<E> {
...省略私有属性...
/**
* 无参构造方法(默认设置elementData数组的空间长度为10)
*/
public ArrayList() {
this(10);
}
/**
* 有参构造方法(指定设置elementData数组的空间长度)
* @param cap 设置数组的空间长度
*/
public ArrayList(int cap) {
// 1.判断cap不合法的情况
if (cap < 0) {
throw new IllegalArgumentException("参数不合法,cap:" + cap);
}
// 2.执行此处,证明cap合法,则对elementData做实例化操作
this.elementData = new Object[cap];
}
}具备添加元素和扩容方法
/**
* 模拟ArrayList集合
*/
public class ArrayList<E> {
...省略私有属性和构造方法...
/**
* 添加元素操作
* @param element 需要添加的元素
*/
public void add(E element) {
// 1.判断elementData数组是否需要扩容
ensureCapacityInternal();
// 2.把element添加进入elementData数组中
elementData[size] = element;
// 3.添加元素之后,size执行递增操作
size++;
}
/**
* 判断数组是否需要扩容
*/
private void ensureCapacityInternal() {
// 1.当数组的空间长度和实际存放元素个数相同时,则执行扩容操作
if (elementData.length == size) {
// 2.创建一个比elementData数组长度更大的新数组
Object[] newArr = new Object[size + (size >> 1)];
// 3.把elementData数组中的元素依次的拷贝进入newArr数组中
System.arraycopy(elementData, 0, newArr, 0, size);
// 4.让elementData指向扩容后的新数组
this.elementData = newArr;
}
}
}具备获取元素方法;先检查索引值index是否合法,此处index的合法索引取值范围在[0, size - 1]之间,然后执行获取元素的操作
/**
* 模拟ArrayList集合
*/
public class ArrayList<E> {
...省略私有属性和构造方法...
/**
* 根据索引获取元素
* @param index 索引值
* @return 返回index所对应的元素值
*/
public E get(int index) {
// 1.判断index索引是否合法,合法的索引取值范围在[0, size-1]之间
if (index < 0 || index >= size) {
throw new ArrayIndexOutOfBoundsException("数组索引越界异常");
}
// 2.执行到此处,证明index取值肯定合法,数组的元素值
return (E) elementData[index];
}
/**
* 获取集合中实际添加元素的个数
* @return
*/
public int size() {
return this.size;
}
}具备修改元素方法,先检查索引值index是否合法,此处index的合法索引取值范围在[0, size-1]之间,然后执行修改操作
/**
* 模拟ArrayList集合
*/
public class ArrayList<E> {
...省略私有属性和构造方法...
/**
* 根据索引修改元素
* @param index 修改的索引位置
* @param element 修改后的元素值
* @return 返回被修改的元素值
*/
public E set(int index, E element) {
// 1.判断index索引是否合法,合法的索引取值范围在[0, size-1]之间
if (index < 0 || index >= size) {
throw new ArrayIndexOutOfBoundsException("数组索引越界异常");
}
// 2.获取被替换的元素
Object oldValue = elementData[index];
// 3.修改索引为index的元素
elementData[index] = element;
// 4.返回替换元素的值
return (E) oldValue;
}
}具备插入元素方法;先检查传入的index索引是否合法(此处index的合法取值范围在[0, size]之间),然后判断数组是否需要扩容,接着将插入索引及其之后的元素往后挪动一位,最后再插入元素
/**
* 模拟ArrayList集合
*/
public class ArrayList<E> {
...省略私有属性和构造方法...
/**
* 根据索引插入元素
* @param index 插入的索引位置
* @param element 插入的元素值
*/
public void add(int index, E element) {
// 1. 判断index索引是否合法,合法的索引取值范围在[0, size]之间
if(index < 0 || index > this.size)
throw new IndexOutOfBoundsException("插入索引越界");
// 2.检查数组是否需要扩容
ensureCapacityInternal();
// 3.将插入索引及其之后的元素完后挪动一位
System.arraycopy(elementData, index,elementData, index + 1, size - index);
// 4.在指定索引位置插入元素
elementData[index] = element;
// 5.实际添加元素个数+1
size++;
}
}具备根据索引删除元素方法;首先先判断索引是否合法,然后将删除索引之后的元素依次往前挪动一位,接着把数组中最后一个元素设置为默认值(null)
/**
* 模拟ArrayList集合
*/
public class ArrayList<E> {
...省略私有属性和构造方法...
/**
* 根据索引删除元素
* @param index 删除的索引位置
* @return 返回被删除的元素值
*/
public E remove(int index) {
// 1.判断index索引是否合法,合法的索引取值范围在[0, size-1]之间
if (index < 0 || index >= size) {
throw new ArrayIndexOutOfBoundsException("数组索引越界异常");
}
// 2.获取删除索引对应的元素
Object oldValue = elementData[index];
// 3.删除索引为index的元素
fastRemove(index);
// 4.返回被删除的元素
return (E) oldValue;
}
/**
* 删除索引为index的元素
* @param index 删除的索引位置
*/
private void fastRemove(int index) {
// 1.将删除索引之后的元素依次往后挪动一位
System.arraycopy(elementData, index + 1, elementData, index, size - index - 1);
// 2.把最后一个元素设置为默认值
elementData[size - 1] = null;
// 3.删除元素后,则实际添加元素个数-1
size--;
}
}具备删除指定元素方法;首先找到删除元素在数组中所在的索引位置,如果没有找到则证明移除失败,如果找到则进行根据索引来移除元素的操作
/**
* 模拟ArrayList集合
*/
public class ArrayList<E> {
...省略私有属性和构造方法...
/**
* 删除指定的某个元素
* @param element 要删除的元素
* @return 返回true,代表删除成功;返回false,代表删除失败
*/
public boolean remove(E element) {
// 因为集合中可以存放null,所以判断之前需判断元素是否为null
if(element == null) {
for (int index = 0; index < size; index++)
// 如果遍历出来的元素为null,则执行删除操作
if (elementData[index] == null) {
fastRemove(index);
return true;
}
}else{
for (int index = 0; index < size; index++)
// 如果遍历出来元素和删除元素相等,则执行删除操作
if (element.equals(elementData[index])) {
fastRemove(index);
return true;
}
}
// 执行到此处,则意味着删除元素失败,那么返回false
return false;
}
/**
* 删除索引为index的元素
* @param index 删除的索引位置
*/
private void fastRemove(int index) {
// 1.将删除索引之后的元素依次往后挪动一位
System.arraycopy(elementData, index + 1, elementData, index, size - index - 1);
// 2.把最后一个元素设置为默认值
elementData[size - 1] = null;
// 3.删除元素后,则实际添加元素个数-1
size--;
}
}
定义和使用
方式1,普通方式,支持任意Object类型的对象
实例代码
package com.bjpowernode.demo;
import java.util.ArrayList;
import java.util.List;
/**
* Collection集合类示例
*/
public class CollectionDemo {
public static void main(String[] args) {
//定义
//支持任意Object类型的对象
ArrayList datas = new ArrayList();
//使用-设置
//添加整数,会将整数字面量装箱成Integer包装类,然后添加到集合
datas.add(1);
//添加小数,会将整数字面量装箱成Double包装类,然后添加到集合
datas.add(0.1);
//添加字符串
datas.add("abc");
//添加自定义类型对象
datas.add(new Student());
//使用-获取
Object obj = datas.get(0); //正确
Double doubleReferenc = datas.get(1); //错误,不支持从Object到Double类型的自动类型转换
double doubleVariable = datas.get(1); //错误,不支持从Object到double基本数据类型的转换
String stringReferenct = datas.get(2); //错误,不支持从Object到String引用数据类型的转换
Student student = datas.get(3); //错误,不支持从Object到Student引用数据类型的转换
}
}方式2,泛型方式,常用方式,只支持指定类型的对象
实例代码
package com.bjpowernode.demo;
import java.util.ArrayList;
import java.util.List;
/**
* Collection集合类示例
*/
public class CollectionDemo {
public static void main(String[] args) {
//定义
//定义只支持Integer类型的集合
List<Integer> integerDatas = new ArrayList <>();
//定义只支持String类型的集合
List<String> stringDatas = new ArrayList <>();
//定义只支持自定义类型的集合
List<Student> students = new ArrayList <>();
//使用-设置
integerDatas.add(1); //正确
integerDatas.add(new Integer(2)); //正确
integerDatas.add(3.3); //错误,无法将double自动转型成Integer
stringDatas.add("abc"); //正确
stringDatas.add(new String("abc")); //正确
stringDatas.add(123); //错误,无法将int自动转型成String
students.add(new Student()); //正确
students.add(new Bird()); //错误,无法将Bird类型自动转型成Student
//使用-获取
Integer integerReference = integerDatas.get(0); //正确
int intVariable = integerDatas.get(0); //正确
Long longReference = integerDatas.get(0); //错误,无法将包装类Integer转换成Long
long longVariable = integerDatas.get(0); //正确,会里德拆箱,并兼容
String stringReference = stringDatas.get(0); //正确
Student student = students.get(0); //正确
Object object = students.get(0); //正确,会进行自动类型转换
Bird bird = students.get(0); //错误,无法将Student类型转换成Bird类型
}
}
应用实例
实例1,使用for循环遍历;汇总整型数据
实例代码
package com.bjpowernode.demo;
import java.util.ArrayList;
import java.util.List;
/**
* ArrayList示例
*/
public class ArrayListDemo {
public static void main(String[] args) {
//定义ArrayList对象
List <Integer> datas = new ArrayList <>();
//添加数据
datas.add(11);
datas.add(22);
datas.add(33);
datas.add(99);
//遍历汇总
int sum = 0;
for (int index = 0; index < datas.size(); index++) {
sum += datas.get(index);
}
//输出
System.out.println("汇总结果:" + sum);
}
}输出结果,运行查看结果
实例2,使用foreach循环遍历;汇总国外订单中的产品总数
实例代码
package com.bjpowernode.demo;
import java.util.ArrayList;
import java.util.List;
import java.util.Scanner;
/**
* 订单类,汇总海外订单的产品总数
*/
public class Order {
private Integer no; //订单编号
private Integer productCount; //订单产品数量
private String remark; //订单备注
private Boolean isForeign; //是否为国外订单
/**
* 入口方法
*
* @param args
*/
public static void main(String[] args) {
//定义标准输入对象
Scanner scanner = new Scanner(System.in);
//定义接收数据的集合
List <Order> orders = new ArrayList <>();
//接收用户输入,直到输出的产品编号小于0为止
//定义订单引用,接收用户输入
Order order;
while (true) {
System.out.println("------------请输入产品信息------------");
order = new Order();
System.out.print("订单编号:");
order.setNo(scanner.nextInt());
//如果订单编号小于0,退出循环;否则,将输入产品添加到集合
if (order.getNo() != null && order.getNo().intValue() < 0) {
break;
} else {
orders.add(order);
}
System.out.print("产品数量:");
order.setProductCount(scanner.nextInt());
System.out.print("备注:");
order.setRemark(scanner.next());
System.out.print("是否国外订单?");
order.setForeign(scanner.nextBoolean());
}
//遍历汇总,其实也可以在输入的时候汇总
int foreignProductSum = 0;
for (Order item : orders) {
if (item.getForeign() == true) {
foreignProductSum += item.getProductCount();
}
}
System.out.println("------------国外订单汇总信息------------");
//输出
System.out.println("国外订单产品总数:" + foreignProductSum);
}
public Integer getNo() {
return no;
}
public void setNo(Integer no) {
this.no = no;
}
public Integer getProductCount() {
return productCount;
}
public void setProductCount(Integer productCount) {
this.productCount = productCount;
}
public String getRemark() {
return remark;
}
public void setRemark(String remark) {
this.remark = remark;
}
public Boolean getForeign() {
return isForeign;
}
public void setForeign(Boolean foreign) {
isForeign = foreign;
}
}输出结果,运行查看结果
实例3,常用方法的使用
学生类
package com.bjpowernode.listdemo;
/**
* 学生类
*/
public class Student {
private Integer id;
private String name;
public Student(Integer id, String name) {
this.id = id;
this.name = name;
}
public Integer getId() {
return id;
}
public void setId(Integer id) {
this.id = id;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
@Override
public String toString() {
return "Student{" +
"id=" + id +
", name='" + name + '\'' +
'}';
}
}ArrayList常用方法使用
package com.bjpowernode.listdemo;
import java.util.ArrayList;
import java.util.List;
/**
* ArrayList常用方法使用
*/
public class ArrayListDemo {
public static void main(String[] args) {
//定义ArrayList
List<Student> students = new ArrayList<>();
//初始化数据,【add方法】
Student student = new Student(1,"张三");
students.add(student);
student = new Student(2,"李四");
students.add(student);
student = new Student(3,"王五");
students.add(student);
//输出列表内容
System.out.println("----------初始内容----------");
System.out.println(students);
//【size方法】
System.out.println("----------size----------");
System.out.println(students.size());
//【get方法】
System.out.println("----------get----------");
//获取第1个元素并输出
Student temp = students.get(0);
System.out.println(temp.toString());
//获取第3个元素并输出
temp = students.get(2);
System.out.println(temp.toString());
//【remove方法】
System.out.println("----------remove----------");
//根据序号删除
System.out.println("----根据序号删除----");
System.out.println("【删除前数据】");
System.out.println(students);
students.remove(0);
System.out.println("【删除后数据】");
System.out.println(students);
//根据对象删除
System.out.println("----根据对象删除(错误方式)----");
System.out.println("【删除前数据】");
System.out.println(students);
//能不能删除?
Student zs = new Student(2,"李四");
students.remove(zs);
System.out.println("【删除后数据】");
System.out.println(students);
System.out.println("----根据对象删除(正确方式)----");
System.out.println("【删除前数据】");
System.out.println(students);
//能不能删除?
Student ls = students.get(0);
students.remove(ls);
System.out.println("【删除后数据】");
System.out.println(students);
//【set方法】
System.out.println("----------set----------");
System.out.println("【修改前数据】");
System.out.println(students);
temp = new Student(9,"王小波");
students.set(0,temp);
System.out.println("【修改后数据】");
System.out.println(students);
//【contains方法】
System.out.println("----------contains----------");
System.out.println("----根据对象包含(正确方式)----");
boolean result = students.contains(temp);
System.out.println("是否包含:"+result);
System.out.println("----根据对象包含(错误方式)----");
temp = new Student(9,"王小波");
result = students.contains(temp);
System.out.println("是否包含:"+result);
//【isEmpty方法】
System.out.println("----------isEmpty方法----------");
System.out.println("是否为空:"+students.isEmpty());
students.clear(); //清除所有数据
System.out.println("是否为空:"+students.isEmpty());
}
}
【练习】
- 练习应用实例内容,完成代码编写
- 【扩展】重构程序,将第16章-包装类中的练习产品和仓库进行重构,要求如下
- 产品列表使用List类型
- 添加方法:
- 新增产品,形参为Product类对象,返回新增是否成功;注意,如果产品编号已经存在,则不能新增
- 修改产品,形参为Product类对象,返回修改是否成功;
- 删除产品,形参为产品编号,返回删除是否成功
- 测试上述方法
LinkedList【扩展】
链式存储结构
单链表
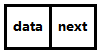
单链表采用的是链式存储结构,使用一组地址任意的存储单元来存放数据元素
在单链表中,存储的每一条数据都是以节点来表示的,每个节点的构成为:元素(存储数据的存储单元) + 指针(存储下一个节点的地址值)
单链表的节点结构如下图所示
另外,单链表中的开始节点,我们又称之为首节点;单链表中的终端节点,我们又称之为尾节点。如下图所示

根据序号获取节点操作
在线性表中,每个节点都有一个唯一的序号,该序号是从0开始递增的。通过序号获取单链表的节点时,我们需要从单链表的首节点开始,从前往后循环遍历,直到遇到查询序号所对应的节点时为止 以下图为例,我们需要获得序号为2的节点,那么就需要依次遍历获得“节点11”和“节点22”,然后才能获得序号为2的节点,也就是“节点33”
在链表中通过序号获得节点的操作效率是非常低的
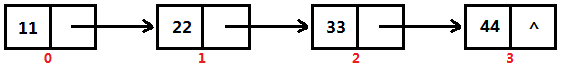
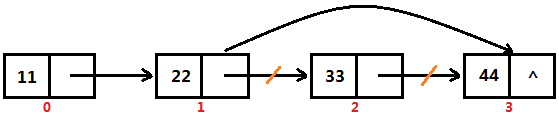
根据序号删除节点操作
根据序号删除节点的操作,我们首先应该根据序号获得需要删除的节点,然后让“删除节点的前一个节点”指向“删除节点的后一个节点”,这样就实现了节点的删除操作 以下图为例,我们需要删除序号为2的节点,那么就让“节点22”指向“节点44”即可,这样就删除了序号为2的节点,也就是删除了“节点33”
通过序号来插入节点,时间主要浪费在找正确的删除位置上。但是,单论删除的操作,也就是无需考虑定位到删除节点的位置
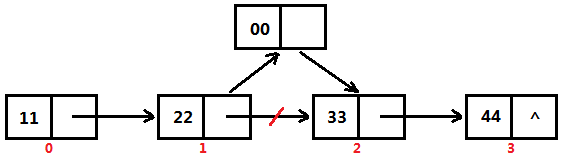
根据序号插入节点操作
根据序号插入节点的操作,我们首先应该根据序号找到插入的节点位置,然后让“插入位置的上一个节点”指向“新插入的节点”,然后再让“新插入的节点”指向“插入位置的节点”,这样就实现了节点的插入操作。 以下图为例,我们需要在序号为2的位置插入元素值“00”,首先先把字符串“00”封装为一个节点对象,然后就让“节点22”指向“新节点00”,最后再让“节点00”指向“节点33”,这样就插入了一个新节点。
通过序号来插入节点,时间主要浪费在找正确的插入位置上。但是,单论插入的操作,也就是无需考虑定位到插入节点的位置
双链表
双链表也叫双向链表,它依旧采用的是链式存储结构。在双链表中,每个节点中都有两个指针,分别指向直接前驱节点(保存前一个节点的地址值)和直接后继节点(保存后一个节点的地址值),如下图所示
所以,从双链表中的任意一个节点开始,都可以很方便地访问它的直接前驱节点和直接后继节点,如下图所示

单链表和双链表的区别
- 单链表:对于一个节点,有储存数据的data和指向下一个节点的next。也就是说,单链表的遍历操作都得通过前节点—>后节点
- 双链表:对于一个节点,有储存数据的data和指向下一个节点的next,还有一个指向前一个节点的pre。也就是说,双链表不但可以通过前节点—>后节点,还可以通过后节点—>前节点
环形链表
环形链表依旧采用的是链式存储结构,它的特点就是设置首节点和尾节点相互指向,从而实现让整个链表形成一个环。在我们实际开发中,常见的环形链表有
环形单链表,在单链表中,尾节点的指针指向了首节点,从而整个链表形成一个环,如下图所示

环形双链表,在双链表中,尾节点的指针指向了首节点,首节点的指针指向了尾节点,从而整个链表形成一个环,如下图所示

源码解析
LinkedList集合底层采用双向链表实现的存储,也就意味着LinkedList集合采用的是链式存储结构。在双链表中,每个节点中都有两个指针,分别指向前一个节点(保存前一个节点的地址值)和后一个节点(保存后一个节点的地址值)
LinkedList集合的特点为:查询效率低,增删效率高,线程不安全。我们打开LinkedList源码,可以看到里面包含了双向链表的相关代码

源码中Node类中包含了item、next和prev三个成员变量,其中item保存了节点中存储的数据,next和prev分别指向了后一个节点和前一个节点,则意味着Node类就是双向链表的节点类
将接下来,我们再继续看LinkeList集合包含了哪些属性,源码如下
源码中first属性保存的就是双链表的首节点,last属性保存的就是双链表的尾结点,而size属性保存了双链表实际存放元素的个数。
因此,对LinkedList集合的操作,其实就是对双链表做的操作,下面我们来模拟LinkedList集合的底层实现

因为LinkedList类属于Deque接口的实现类,也就意味着LinkedList集合对比List接口新增了一些方法,这些新增的方法都是实现于Deque接口的方法,新增的部分方法如下
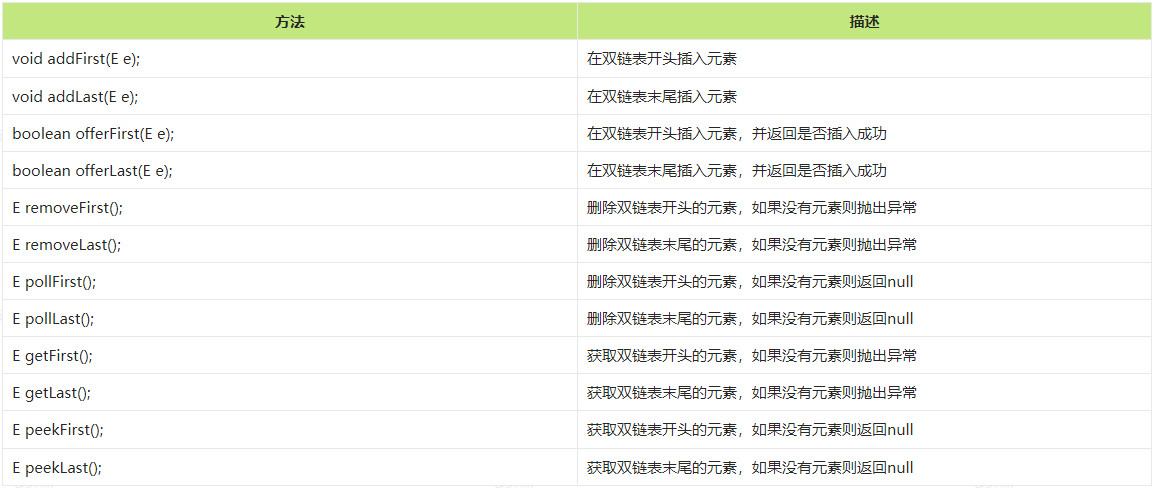
节点类的定义,双链表节点类很简单,item用于存储节点中的数据,prev用于存储前一个节点的地址值,next用于存放前后一个节点的地址
/**
* 模拟LinkedList集合
*/
public class LinkedList<E> {
/**
* 节点类
* @param <E> 指的就是节点中存储“元素”的类型
*/
private static class Node<E> {
/**
* 定义一个变量,用于保存前一个节点的地址值
*/
private Node<E> prev;
/**
* 定义一个变量,用于保存节点中的数据
*/
private E item;
/**
* 定义一个变量,用于保存后一个节点的地址值
*/
private Node<E> next;
/**
* 有参构造方法(为item、prev和next做初始化)
* @param prev
* @param item
* @param next
*/
public Node(Node<E> prev, E item, Node<E> next) {
this.item = item;
this.prev = prev;
this.next = next;
}
}
}私有属性,共3个
/**
* 模拟LinkedList集合
*/
public class LinkedList<E> {
/**
* 存储双链表首节点
*/
private Node<E> firstNode;
/**
* 存储双链表尾节点
*/
private Node<E> lastNode;
/**
* 存储实际添加元素的个数
*/
private int size;
/**
* 获得实际添加元素的个数
* @return
*/
public int size() {
return size;
}
...省略双链表节点类...
}添加元素方法,在链表的尾部追加一个节点,但是要注意判断当前链表是否为空链表
/**
* 模拟LinkedList集合
*/
public class LinkedList<E> {
...省略私有属性和构造方法...
/**
* 添加元素
* @param element
*/
public void add(E element) {
// 1.把元素内容包装为一个节点对象
Node<E> node = new Node<>(null, element, null);
// 2.如果双链表不存在尾结点,则证明双链表还不存在
if (lastNode == null) {
// 把node节点设置为首节点
firstNode = node;
}
// 3.如果双链表中存在尾节点,那么把尾节点和node链接起来
else {
// 把尾节点和node链接起来
lastNode.next = node;
node.prev = lastNode;
}
// 4.更新双链表的尾节点
lastNode = node;
// 5.设置实际添加元素个数+1
size++;
}
...省略双链表节点类..
}获取元素方法,获取双链表中指定序号(此处序号类似于数组的索引)的元素,首先需要判断序号是否合法,然后通过循环来找到对应序号的节点,从而拿到节点中存放的内容
/**
* 模拟LinkedList集合
*/
public class LinkedList<E> {
...省略私有属性和构造方法...
/**
* 根据序号获得元素
* @param index 序号值
* @return 返回序号对应的元素
*/
public E get(int index) {
// 1.检查index的取值是否合法
if (index < 0 || index >= size)
throw new IndexOutOfBoundsException("链表序号越界异常");
// 2.获取元素节点的内容
return node(index).item;
}
/**
* 根据序号获得节点对象
* @param index 序号
* @return 返回index对应的节点对象
*/
private Node<E> node(int index) {
// 1.如果索引在前半区,则“从前往后”开始查找
if (index < (size >> 1)) {
// 1.1准备开始从首节点开始查找
Node<E> currentNode = firstNode;
// 1.2从前往后遍历节点,一直到index所在位置
for (int i = 0; i < index; i++)
// 获得当前节点的下一个节点
currentNode = currentNode.next;
// 1.3返回找到的节点
return currentNode;
}
// 2.如果索引在后半区,则“从后往前”开始查找
else {
// 2.1准备开始从尾节点开始查找
Node<E> currentNode = lastNode;
// 2.2从后往前遍历节点,一直到index所在位置
for (int i = size - 1; i > index; i--)
// 获得当前节点的下一个节点
currentNode = currentNode.prev;
// 2.3返回找到的节点
return currentNode;
}
}
...省略双链表节点类..
}修改元素方法,根据序号修改元素,首先判断序号取值是否合法,然后通过循环来找到对应序号位置的节点,最后再修改节点中存放的内容
/**
* 模拟LinkedList集合
*/
public class LinkedList<E> {
...省略私有属性和构造方法...
/**
* 根据序号修改元素
* @param index 序号
* @param element 元素
* @return 返回被修改的元素值
*/
public E set(int index, E element) {
// 1.检查index的取值是否合法
if (index < 0 || index >= size)
throw new IndexOutOfBoundsException("链表序号越界异常");
// 2.根据索引获取元素节点
Node<E> node = node(index);
// 3.获取节点以前存放的内容
E oldVal = node.item;
// 4.修改节点中存放的内容
node.item = element;
// 5.返回节点修改之前的内容
return oldVal;
}
/**
* 根据序号获得节点对象
* @param index 序号
* @return 返回index对应的节点对象
*/
private Node<E> node(int index) {
// 1.如果索引在前半区,则“从前往后”开始查找
if (index < (size >> 1)) {
// 1.1准备开始从首节点开始查找
Node<E> currentNode = firstNode;
// 1.2从前往后遍历节点,一直到index所在位置
for (int i = 0; i < index; i++)
// 获得当前节点的下一个节点
currentNode = currentNode.next;
// 1.3返回找到的节点
return currentNode;
}
// 2.如果索引在后半区,则“从后往前”开始查找
else {
// 2.1准备开始从尾节点开始查找
Node<E> currentNode = lastNode;
// 2.2从后往前遍历节点,一直到index所在位置
for (int i = size - 1; i > index; i--)
// 获得当前节点的下一个节点
currentNode = currentNode.prev;
// 2.3返回找到的节点
return currentNode;
}
}
...省略双链表节点类..
}插入元素方法,在链表中指定序号位置插入元素,首先判断序号的取值是否合法,然后通过循环来找到对应索引位置的节点,最后执行插入操作,而插入操作核心就是修改节点之间的指向
/**
* 模拟LinkedList集合
*/
public class LinkedList<E> {
...省略私有属性和构造方法...
/**
* 根据序号插入元素
* @param index 序号
* @param element 插入的元素
*/
public void add(int index, E element) {
// 1.检查index取值是否合法
if (index < 0 || index > size)
throw new IndexOutOfBoundsException("链表序号越界异常");
// 2.节点插入操作
// 2.1如果index和size相等,那么意味着添加到双链表末尾
if (index == size) {
// 2.2调用add()方法,将元素添加到集合的末尾
add(element);
}
// 2.2如果index和size不相等,则进行插入操作
else {
// 2.3根据索引获取链表中的节点
Node<E> node = node(index);
// 2.4进行插入操作
linkBefore(element, node);
// 2.5链表中节点递增
size++;
}
}
/**
* 插入节点操作
* @param element 插入的元素
* @param targetNode 目标节点(插入位置节点)
*/
public void linkBefore(E element, Node<E> targetNode) {
// 1.获取目标节点的上一个节点
Node<E> preNode = targetNode.prev;
// 2.把元素内容包装为一个节点对象
Node<E> newNode = new Node<>(preNode, element, targetNode);
// 3.把targetNode节点的prev指向newNode
targetNode.prev = newNode;
// 4.把preNode的next指向newNode
// 4.1如果preNode存在,正常处理
if (preNode != null)
preNode.next = newNode;
// 4.2如果preNode不存在,则证明newNode为首节点
else
firstNode = newNode;
}
...省略双链表节点类...
}删除元素方法
根据序号来删除集合元素,首先先判断序号取值是否合法,然后通过循环来找到对应索引位置的节点,最后删除该节点,而删除操作核心就是修改节点之间的指向
/**
* 模拟LinkedList集合
*/
public class LinkedList<E> {
...省略私有属性和构造方法...
/**
* 根据序号删除元素
* @param index 序号
* @return 返回被删除的元素
*/
public E remove(int index) {
// 1.检查index的取值是否合法
if (index < 0 || index >= size)
throw new IndexOutOfBoundsException("链表序号越界异常");
// 2.找到需要删除的节点对象
Node<E> node = node(index);
// 3.获取被删除节点中存放的内容
E value = node.item;
// 4.执行移除节点操作
unlink(node);
// 5.返回被删除节点的内容
return value;
}
/**
* 执行删除节点的操作
* @param node 需要删除的节点
*/
public void unlink(Node<E> node) {
// 1.获取被移除节点的上一个节点和下一个节点
Node<E> prev = node.prev;
Node<E> next = node.next;
// 2.判断prev是否为空
if(prev == null)
// 2.1prev为null,则证明删除node后,next就为链表的首节点
firstNode = next;
else
// 2.2prev不为null,则把prev.next设置为next
prev.next = next;
// 3.判断next是否为空
if(next == null)
// 3.1next为null,则证明删除node后,prev就为链表的尾节点
lastNode = prev;
else
// 3.2next不为null,则把next.prev设置为prev
next.prev = prev;
// 4.释放node对象的引用关系
node.next = null;
node.prev = null;
node.item = null;
// 5.链表中节点递减
size--;
}
...省略双链表节点类...
}删除链表中指定某个元素,首先找到该元素在链表中所在的位置,如果没有找到则证明移除失败,如果找到则删除该节点
/**
* 模拟LinkedList集合
*/
public class LinkedList<E> {
...省略私有属性和构造方法...
/**
* 删除指定某个元素
* @param element 需要删除的元素
* @return 删除成功,则返回true;删除失败,则返回false
*/
public boolean remove(E element) {
// 情况一:处理要删除的元素就是null的情况
if(element == null) {
// 通过for循环,从前往后遍历得到双链表中的所有节点
for(Node<E> node = firstNode; node != null; node = node.next) {
// 如果遍历出来的元素为null,则就删除该元素
if(node.item == null) {
// 执行删除节点操作,然后再返回true
unlink(node);
return true;
}
}
}
// 情况二:处理要删除的元素不是null的情况
else {
// 通过for循环,从前往后遍历得到双链表中的所有节点
for(Node<E> node = firstNode; node != null; node = node.next) {
// 如果遍历出来的元素和删除元素相等,则执行删除操作
if(element.equals(node.item)) {
// 执行删除节点操作,然后再返回true
unlink(node);
return true;
}
}
}
// 执行到此处,则意味着删除失败,那么返回false
return false;
}
/**
* 执行删除节点的操作
* @param node 需要删除的节点
*/
public void unlink(Node<E> node) {
// 1.获取被移除节点的上一个节点和下一个节点
Node<E> prev = node.prev;
Node<E> next = node.next;
// 2.判断prev是否为空
if(prev == null)
// 2.1prev为null,则证明删除node后,next就为链表的首节点
firstNode = next;
else
// 2.2prev不为null,则把prev.next设置为next
prev.next = next;
// 3.判断next是否为空
if(next == null)
// 3.1next为null,则证明删除node后,prev就为链表的尾节点
lastNode = prev;
else
// 3.2next不为null,则把next.prev设置为prev
next.prev = prev;
// 4.释放node对象的引用关系
node.next = null;
node.prev = null;
node.item = null;
// 5.链表中节点个数递减
size--;
}
...省略双链表节点类...
}
【练习】
- 阅读LinkedList源码
Vector【扩展】
概述
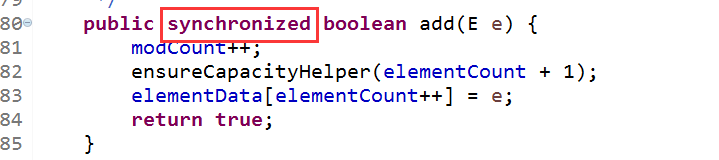
Vector集合和ArrayList集合的用法几乎一模一样,底层都是采用了数组来存储集合中的元素。只不过Vector类的方法都加了同步检查,因此“线程安全,效率低”
比如:add(E e)方法就增加了synchronized同步标记
应用实例
应用实例1,如何使用
public class Test {
public static void main(String[] args) {
// 实例化一个Vector
Vector<String> vector = new Vector<String>();
// 添加元素,addElement()方法和add()方法类似
vector.addElement("java");
vector.addElement("HTML");
vector.addElement("JavaScript");
vector.addElement("CSS");
// 遍历集合, elements()方法类似于iterator()方法
Enumeration<String> elements = vector.elements();
while(elements.hasMoreElements()) {
System.out.println(elements.nextElement());
}
}
}
使用建议
- 需要保证线程安全时,建议选用Vector
- 不存在线程安全问题时,并且查找较多用ArrayList(一般使用它)
- 不存在线程安全问题时,增加或删除元素较多用LinkedList
Set
概述
- 是Collection系列中的类,主要特点是值不能重复
- 常用的子类有HashSet、TreeSet
- HashSet特点
- 无序,不可重复
- 可以有一个null值
- 泛型数据如果有业务上的比较(如比较两个对象是否相同),必须覆盖equals和hashCode方法
- TreeSet特点
- 有序,不可重复;底层使用红黑树实现
- 是SortedSet接口的子类,是一个排序的Set
- 一般泛型数据类型必须实现Comparable接口,并按业务覆盖其中的compareTo方法,进行自然排序,(使用Comparator接口也可以,俗称定制排序)
Set常用方法
- size方法,Set长度
- add方法,往Set中添加一个元素
- remove方法,删除指定元素
- contains方法,是否包含某个元素
- isEmpty方法,集合是否为空,即不包含一个元素
- ...
HashSet
源码解析
HashSet类属于Set接口的实现类,在HashSet类中没有新增任何方法,并且HashSet依旧采用哈希表来实现,因此添加元素对应的类就必须重写hashCode()和equals()方法
在HashSet集合中,底层实际上采用HashMap来存储元素的,因此HashSet集合本质就是一个简化版的HashMap。我们打开HashSet集合的源码,发现里面有一行核心代码
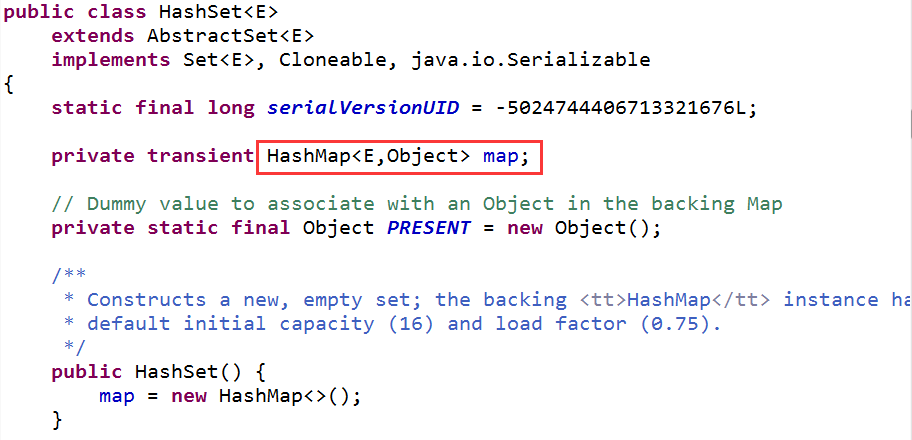
我们发现里面有个map属性,这就是HashSet的核心秘密。我们再看add()方法,发现增加一个元素说白了就是在map中增加一个键值对,键对象就是要添加的元素,值对象是名为PRESENT的Object对象。说白了,就是“往set中加入元素,本质就是把这个元素作为key加入到了内部的HashMap集合中”
由于HashMap集合中的key不能重复的,并且HashMap存储的键值对都是无序的,因此HashSet存储的元素也不能重复,并且HashSet存储的元素还属于无序

定义和使用
方式1,常用方法
package com.bjpowernode.demo;
import java.util.HashSet;
import java.util.Set;
/**
* HashSet常用方法
*/
public class HashSetDemo {
/**
* 入口方法
*
* @param args
*/
public static void main(String[] args) {
//定义Set
Set <Integer> datas = new HashSet <Integer>();
System.out.println("-------------add方法-------------");
//add方法
datas.add(1);
datas.add(2);
datas.add(3);
System.out.println("添加后的数据:" + datas);
//remove方法
System.out.println("-------------remove方法-------------");
datas.remove(2);
System.out.println("删除后的数据:" + datas);
//size方法
System.out.println("-------------size方法-------------");
System.out.println("当前Set的size:" + datas.size());
//contains方法
System.out.println("-------------contains方法-------------");
System.out.println("contains(1):" + datas.contains(1));
System.out.println("contains(99):" + datas.contains(99));
//isEmpty方法
System.out.println("-------------isEmpty方法-------------");
System.out.println("isEmpty():"+datas.isEmpty());
}
}方式2,包装类
package com.bjpowernode.demo;
import java.util.HashSet;
import java.util.Set;
/**
* HashSet包装类示例
*/
public class HashSetDemo {
/**
* 入口方法
* @param args
*/
public static void main(String[] args) {
//定义Set
Set <Integer> datas = new HashSet <>();
//添加元素
datas.add(1);
datas.add(2);
datas.add(3);
datas.add(1); //重复添加
datas.add(1); //重复添加
//输出Set,【注意】,将不会有重复数据
System.out.println(datas);
}
}方式3,自定义类型
工作人员类
package com.bjpowernode.demo;
/**
* 工作人员类
*/
public class Employee {
//姓名
private String name;
//性别
private char sex;
//年龄
private int age;
public Employee(String name, char sex, int age) {
this.name = name;
this.sex = sex;
this.age = age;
}
public Employee() {
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public char getSex() {
return sex;
}
public void setSex(char sex) {
this.sex = sex;
}
public int getAge() {
return age;
}
public void setAge(int age) {
this.age = age;
}
@Override
public String toString() {
return "Employee{" + "name='" + name + '\'' + ", sex=" + sex + ", age=" + age + '}';
}
}测试类
package com.bjpowernode.demo;
import java.util.HashSet;
import java.util.Set;
/**
* HashSet自定义类型示例
*/
public class HashSetDemo {
/**
* 入口方法
*
* @param args
*/
public static void main(String[] args) {
//定义Set
Set <Employee> employees = new HashSet <>();
//定义员工
Employee e1 = new Employee("张三", '男', 18);
Employee e2 = new Employee("李四", '女', 28);
Employee e3 = new Employee("王五", '女', 38);
Employee e4 = new Employee("张三", '男', 18);
//添加到Set
employees.add(e1);
employees.add(e2);
employees.add(e3);
employees.add(e4);
employees.add(e1); //重复添加
employees.add(e1); //重复添加
//输出Set,【注意】,将不会有重复数据
System.out.println(employees);
}
}输出结果,Set中共4个对象
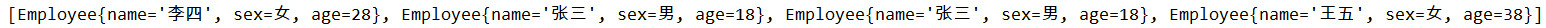
方式4,普通类,如果两个对象在业务上相同,不能重复,怎么办?如上面的e1和e4,业务规则是姓名和年龄相同,则认为是同一个对象,不能重复
- 注意:此时需要覆盖equals方法和hashCode方法,(可通过右键generate...菜单中的equals() and hashCode()子菜单自动实现)
- equals方法:根据业务逻辑比较,如姓名和年龄相同就表示是同一个对象
- hashCode方法:两个相同的对象,需要返回的hashCode值也一样,故需要使用equals中比较的业务字段进行hash算法
工作人员类
package com.bjpowernode.demo;
import java.util.Objects;
/**
* 工作人员类
*/
public class Employee {
//姓名
private String name;
//性别
private char sex;
//年龄
private int age;
/**
* 覆盖Object方法,实现自己业务需要的工作人员比较逻辑
* @param o 要比较的对象
* @return 比较结果,true为相同,false为不相同
*/
@Override
public boolean equals(Object o) {
if (this == o) return true;
if (o == null || getClass() != o.getClass()) return false;
Employee employee = (Employee) o;
return age == employee.age && name.equals(employee.name);
}
/**
* hashCode方法,要保证按业务相同的两个方法,返回的hashCode也要一致;
* 使用Objects的hash方法来实现
* @return
*/
@Override
public int hashCode() {
return Objects.hash(name, age);
}
public Employee(String name, char sex, int age) {
this.name = name;
this.sex = sex;
this.age = age;
}
public Employee() {
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public char getSex() {
return sex;
}
public void setSex(char sex) {
this.sex = sex;
}
public int getAge() {
return age;
}
public void setAge(int age) {
this.age = age;
}
@Override
public String toString() {
return "Employee{" + "name='" + name + '\'' + ", sex=" + sex + ", age=" + age + '}';
}
}- 注意:此时需要覆盖equals方法和hashCode方法,(可通过右键generate...菜单中的equals() and hashCode()子菜单自动实现)
测试类
package com.bjpowernode.demo;
import java.util.HashSet;
import java.util.Set;
/**
* HashSet自定义类型示例,【按业务规则去重】
*/
public class HashSetDemo {
/**
* 入口方法
*
* @param args
*/
public static void main(String[] args) {
//定义Set
Set <Employee> employees = new HashSet <>();
//定义员工
Employee e1 = new Employee("张三", '男', 18);
Employee e2 = new Employee("李四", '女', 28);
Employee e3 = new Employee("王五", '女', 38);
Employee e4 = new Employee("张三", '男', 18);
//添加到Set
employees.add(e1);
employees.add(e2);
employees.add(e3);
employees.add(e4); //【重复添加】因为姓名和年龄相同
employees.add(e1); //重复添加
employees.add(e1); //重复添加
//输出Set,【注意】,将不会有重复数据
System.out.println(employees);
}
}
输出结果,Set中只有3个对象
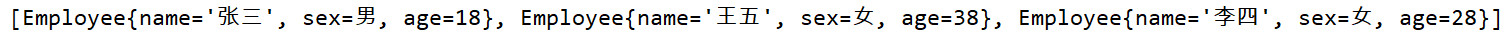
TreeSet
源码解析
TreeSet类属于Set接口的实现类,在TreeSet类中没有新增任何方法,并且底层采用“红黑树”来实现,因此使用TreeSet集合就必须配合“比较器”来实现
在TreeSet集合中,底层实际上采用TreeMap来存储元素的,因此TreeSet集合本质就是一个简化版的TreeMap。我们打开TreeSet集合的源码,发现里面有一行核心代码
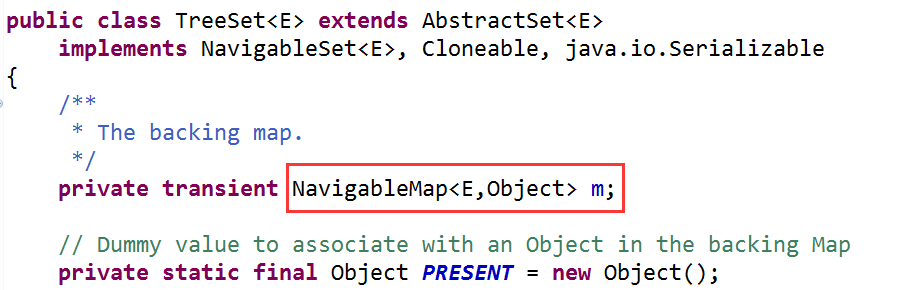
NavigableMap是一个接口,而TreeMap类就属于NavigableMap接口的实现类,因此给m赋值的就可以为TreeMap集合,此处使用了“多态”来实现,分析构造方法源码如下

接下来,我们再分析add()方法的源码,发现增加一个元素就是在TreeMap集合中增加一个键值对,键对象就是添加元素,值对象是名为PRESENT的Object对象。说白了,就是“往TreeSet集合中添加元素,本质就是把这个元素作为key加入到了内部的TreeMap集合中”
因为TreeMap集合存储的key不能重复,并且TreeMap还能根据key实现排序操作,因此TreeSet集合存储的元素也不能重复,并且存储的元素还可以实现排序(升序|降序)操作

定义与使用
方式1,对象必须实现Comparable接口,并覆盖其中的compareTo方法
工作人员类,注意compareTo方法
package com.bjpowernode.demo;
/**
* 工作人员类,实现Comparable接口,并覆盖compareTo方法
*/
public class Employee implements Comparable <Employee> {
//姓名
private String name;
//性别
private char sex;
//年龄
private int age;
public Employee(String name, char sex, int age) {
this.name = name;
this.sex = sex;
this.age = age;
}
public Employee() {
}
/**
* 覆盖compareTo方法,实现两个工作人员比较
* 比较逻辑,使用年龄比较,当前对象年龄大于比较对象年龄,返回1,小于返回-1,相对返回0
* 注意,是否重复,是根据返回是否为0判断
*
* @param o
* @return
*/
@Override
public int compareTo(Employee o) {
if (this.getAge() > o.getAge()) {
return 1;
} else if (this.getAge() < o.getAge()) {
return -1;
} else {
return 0;
}
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public char getSex() {
return sex;
}
public void setSex(char sex) {
this.sex = sex;
}
public int getAge() {
return age;
}
public void setAge(int age) {
this.age = age;
}
@Override
public String toString() {
return "Employee{" + "name='" + name + '\'' + ", sex=" + sex + ", age=" + age + '}';
}
}
测试类,注意定义员工中年龄的顺序
package com.bjpowernode.demo;
import java.util.Set;
import java.util.TreeSet;
/**
* TreeSet示例
*/
public class TreeSetDemo {
public static void main(String[] args) {
//定义Set
Set <Employee> employees = new TreeSet <>();
//定义员工
Employee e1 = new Employee("张三", '男', 18);
Employee e2 = new Employee("李四", '女', 98);
Employee e3 = new Employee("王五", '女', 38);
Employee e4 = new Employee("张三", '男', 18);
//添加到Set
employees.add(e1);
employees.add(e2);
employees.add(e3);
employees.add(e4); //【重复添加】因为姓名和年龄相同
employees.add(e1); //重复添加
employees.add(e1); //重复添加
//输出Set,【注意】,将不会有重复数据
System.out.println(employees);
}
}
输出结果,注意有按年龄排序
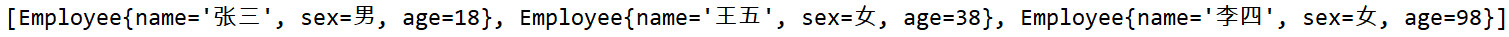
应用简介
【练习】
- 练习应用实例内容,完成代码编写
- 【扩展】重构程序,将第16章-包装类中的练习产品和仓库进行重构,要求如下
- 产品列表使用HashSet类型
- 添加方法:
- 新增产品,形参为Product类对象,返回新增是否成功;注意,如果产品编号已经存在,则不能新增
- 修改产品,形参为Product类对象,返回修改是否成功;
- 删除产品,形参为产品编号,返回删除是否成功
- 测试上述方法
迭代器
概述
- 在Java中,提供了很多集合类,它们在存储元素时,采用的存储方式不同
- 当需要取出这些集合中的元素,可通过一种通用的获取方式来完成,这样使得对容器的遍历操作与其具体的底层实现相隔离,达到解耦的效果
- Collection集合中元素的通用获取方式:在取元素之前先要判断集合中有没有元素,如果有元素则把元素取出,然后继续再判断下一个元素,如果还有就再取出,直到把集合中的所有元素全部取出为止。这种取出方式专业术语称为迭代或迭代器
- 迭代器一般多使用Iterator接口和ListIterator接口
Iterator
对于Iterator接口而言,因为本身是一个接口,所以需要通过Collection接口提供的
Iterator<E> iterator();方法,这样就能获得一个Iterator接口的实现类对象接口主要方法如下

应用实例
应用实例1,使用Iterator遍历
public class Test01 {
public static void main(String[] args) {
// 创建ArrayList集合
ArrayList<String> list = new ArrayList<>();
list.add("aaa");
list.add("bbb");
list.add("ccc");
// 获取集合的迭代器对象
Iterator<String> iterator = list.iterator();
// 迭代器while循环的形式的使用
while(iterator.hasNext()) {
System.out.println(iterator.next());
}
// 迭代器for循环的形式的使用
for(Iterator<String> iter = list.iterator(); iter.hasNext();) {
System.out.println(iter.next());
}
}
}应用实例2,使用迭代器时,通过集合的方法对元素进行操作的错误案例
使用Iterator迭代器遍历集合时,如果集合中已经没有元素了,还继续使用迭代器的next()方法,将会抛出java.util.NoSuchElementException没有集合元素的异常。
如果在迭代过程中,使用了集合的方法对元素进行操作(例如使用集合的方法删除元素)。导致迭代器并不知道集合中的变化,容易引发数据的不确定性,从而会抛出并发修改异常(java.util.ConcurrentModificationException)
public class Test01 {
public static void main(String[] args) {
// 创建ArrayList集合
ArrayList<Integer> list = new ArrayList<Integer>();
list.add(11);
list.add(22);
list.add(33);
// 获取集合的迭代器对象
Iterator<Integer> iterator = list.iterator();
// 使用迭代器来遍历集合中的元素
while (iterator.hasNext()) {
Integer value = iterator.next();
System.out.println(value);
// 当获取的value小于30时,通过集合的方法删除元素
if (value > 30) {
// 通过集合的方法删除元素,会抛出并发修改异常
list.remove(value); // 错误演示
}
}
}
}应用实例3,通过迭代器的remove()方法删除集合元素案例
使用Iterator接口提供的方法只能实现删除元素(remove)操作,如果还想在迭代过程中实现集合的添加元素或修改元素的操作,那么就应该使用ListIterator来实现。
另外,通过for-each遍历集合的过程中,不能通过集合的方法对元素进行操作,否则会抛出并发修改异常,因为for-each循环底层用的就是Iterator来实现的
public class Test01 {
public static void main(String[] args) {
// 创建ArrayList集合
ArrayList<Integer> list = new ArrayList<Integer>();
list.add(11);
list.add(22);
list.add(33);
// 获取集合的迭代器对象
Iterator<Integer> iterator = list.iterator();
// 使用迭代器来遍历集合中的元素
while(iterator.hasNext()) {
Integer value = iterator.next();
System.out.println(value);
// 当获取的value小于30时,通过集合的方法删除元素
if(value > 30) {
// 调用迭代器的方法来删除遍历出来的运算
iterator.remove(); // 正确做法
}
}
}
}
Iterator和foreach的区别
- 使用for-each不但能遍历集合,还能遍历数组,但是使用Iterator只能遍历集合。
- 使用for-each遍历集合时不能删除元素,但是使用Iterator遍历集合时可以删除元素
注意:欲知抛出java.util.ConcurrentModificationException异常的原因,深度解读可查阅这篇博文https://www.cnblogs.com/dolphin0520/p/3933551.html
ListIterator
ListIterator接口继承于Iterator接口,因此ListIterator提供的功能比Iterator更加的强大
使用ListIterator迭代器,不但能“从前往后”遍历集合,还可以“从后往前”遍历集合,并且遍历集合的过程中还能删除、修改和插入元素,常用方法如下

在List接口中,提供了获得ListIterator迭代器的方法,获取方式如下

使用ListIterator迭代器遍历集合,想要实现“从前往后”遍历List集合,则游标位置需要设置为“-1”,也就是建议使用
ListIterator<E> listIterator();来获得迭代器;想要实现“从后往前”遍历List集合,则游标位置需要设置为“实际添加元素的个数”,也就是必须使用ListIterator<E> listIterator(int index);获得迭代器注意:使用Iterator迭代器,只能删除遍历出来的元素;而使用ListIterator迭代器,不但能删除遍历出来的元素,还能修改遍历出来的元素和在遍历出来元素之前或之后插入元素
应用实例
应用实例1,从前往后”遍历ArrayList集合
public class Test01 {
public static void main(String[] args) {
// 创建ArrayList集合
ArrayList<String> list = new ArrayList<>();
// 添加元素
list.add("aaa");
list.add("bbb");
list.add("ccc");
// 获得迭代器,用于“从前往后”遍历集合
ListIterator<String> iterator = list.listIterator();
// 如果存在下一个元素,则执行循环
while(iterator.hasNext()) {
// 获得集合中的下一个元素并输出
System.out.println(iterator.next());
}
}
}应用实例2,“从前往后”遍历ArrayList集合
public class Test01 {
public static void main(String[] args) {
// 创建ArrayList集合
ArrayList<String> list = new ArrayList<>();
// 添加元素
list.add("aaa");
list.add("bbb");
list.add("ccc");
// 获得迭代器,用于“从后往前”遍历集合
ListIterator<String> iterator = list.listIterator(list.size());
// 如果存在前一个元素,则执行循环
while (iterator.hasPrevious()) {
// 获得集合中的前一个元素并输出
System.out.println(iterator.previous());
}
}
}应用实例3,迭代过程中对ArrayList元素操作
public class Test01 {
public static void main(String[] args) {
// 创建ArrayList集合
LinkedList<Integer> list = new LinkedList<Integer>();
// 添加元素
list.add(10);
list.add(20);
list.add(30);
// 获得迭代器,用于“从前往后”遍历集合
ListIterator<Integer> iterator = list.listIterator();
// 如果还存在下一个元素,则执行循环
while(iterator.hasNext()) {
// 获得遍历出来的元素
Integer value = iterator.next();
// 遍历集合的过程中,执行删除、修改和插入操作
if(value <= 10) {
iterator.remove(); // 删除当前迭代的这个元素
} else if (value <= 20) {
iterator.set(22); // 修改当前迭代的这个元素
} else {
iterator.add(40); // 在遍历出来元素后面添加元素
}
}
System.out.println(list); // 输出:[22, 30, 40]
}
}
Iterator和ListIterator的区别
- Iterator应用于Set集合和List集合,但是ListIterator只能应用于List集合
- Iterator只能从前往后遍历集合,而ListIterator能从前往后和从后往前遍历集合
- Iterator只有remove()方法,而ListIterator有remove()、add()和set()方法
【练习】
- 练习应用实例内容,完成代码编写
Collections工具类
实际工作中,会经常对Collection系列和Map系列进行操作
Java中提供了Collections工具类,里面包含了很多针对集合的静态方法,主要是针对Collection系列的数据进行操作
常用方法
- reverse,反转数据
- shuffle,随机数据
- sort,对数据进行排序,对于自定义类型,需要用到Comparator接口匿名类定义比较逻辑
- max,取数据中的最大值,对于自定义类型,需要用到Comparator接口匿名类定义比较逻辑
- min,取数据中的最小值,对于自定义类型,需要用到Comparator接口匿名类定义比较逻辑
- ...
应用实例
应用实例1,常用方法
用户类
package com.bjpowernode.demo;
/**
* 用户类
*/
public class User implements Comparable<User> {
//普通属性
private Integer id;
private String name;
private String sex;
private Integer age;
private Boolean enabled;
/**
* 无参构造方法
*/
public User(){
}
/**
* 有参构造
* @param id
* @param name
* @param sex
* @param enabled
*/
public User(Integer id, String name, String sex, Integer age, boolean enabled){
this.id=id;
this.name=name;
this.sex= sex;
this.age = age;
this.enabled =enabled;
}
public Integer getAge() {
return age;
}
public void setAge(Integer age) {
this.age = age;
}
public Integer getId() {
return id;
}
public void setId(Integer id) {
this.id = id;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public String getSex() {
return sex;
}
public void setSex(String sex) {
this.sex = sex;
}
public Boolean isEnabled() {
return enabled;
}
public void setEnabled(Boolean enabled) {
this.enabled = enabled;
}
@Override
public String toString() {
return "[ID:"+this.id+",姓名:"+this.name+",性别:"+this.sex+",年龄:"+this.age+",是否有效:"+this.isEnabled()+"]";
}
/**
* 【自然排序】覆盖Comparable接口方法,实现按id排序;一般写好了就固定了,灵活较低
* @param o
* @return
*/
@Override
public int compareTo(User o) {
if(this.getId()>o.getId()){
return 1;
}else if(this.getId()<o.getId()){
return -1;
}else{
return 0;
}
}
}Collections示例类
package com.bjpowernode.demo;
import java.util.ArrayList;
import java.util.Collections;
import java.util.Comparator;
import java.util.List;
/**
* Collections工具类,针对ArrayList的使用
*/
public class CollectionsDemo {
public static void main(String[] args) {
//初始化数据
List<User> users = new ArrayList <>();
users.add(new User(1, "张三", "male", 55, true));
users.add(new User(2, "李四", "male", 44, false));
users.add(new User(3, "王五", "female", 20, true));
users.add(new User(4, "赵六", "male", 57, false));
users.add(new User(5, "田七", "female", 18, false));
//输出原始数据
System.out.println("-----------------------------原始数据-----------------------------");
for (User user : users) {
System.out.println(user.toString());
}
//反转
Collections.reverse(users);
//输出反转后的数据
System.out.println("-----------------------------反转后的数据-----------------------------");
for (User user : users) {
System.out.println(user.toString());
}
//随机
Collections.shuffle(users);
//输出随机后的数据
System.out.println("-----------------------------随机后的数据-----------------------------");
for (User user : users) {
System.out.println(user.toString());
}
//自然排序
System.out.println("-----------------------------【自然排序】排序后的数据-----------------------------");
//自然排序,也称内排序,类写好了就固定了;一般写好了就固定了,灵活较低
Collections.sort(users);
//输出排序后的数据
for (User user : users) {
System.out.println(user.toString());
}
//定制排序
System.out.println("-----------------------------【定制排序】排序后的数据-----------------------------");
//定制排序,也称外排序,使用匿名类;相对较灵活
Collections.sort(users, new Comparator<User>() {
@Override
public int compare(User o1, User o2) {
//按年龄排序
if (o1.getAge() > o2.getAge()) {
return 1;
} else {
return -1;
}
}
});
//输出排序后的数据
for (User user : users) {
System.out.println(user.toString());
}
//最大值&最小值
System.out.println("-----------------------------【最大值&最小值】数据-----------------------------");
User maxUser = Collections.max(users, new Comparator <User>() {
@Override
public int compare(User o1, User o2) {
//按年龄比较
if (o1.getAge() > o2.getAge()) {
return 1;
} else {
return -1;
}
}
});
System.out.println("最大年龄用户:"+maxUser.toString());
User minUser = Collections.min(users, new Comparator <User>() {
@Override
public int compare(User o1, User o2) {
//按年龄比较
if (o1.getAge() > o2.getAge()) {
return 1;
} else {
return -1;
}
}
});
System.out.println("最小年龄用户:"+minUser.toString());
}
}
输出结果,运行查看
【练习】
- 练习应用实例内容,完成代码编写
- 【扩展】重构程序,针对“第16章-包装类”中的练习产品和仓库进行应用,要求如下
- 列出仓库产品数量排行榜,降序
- 列出仓库库存金额排行榜,降序
- 找出单价最昂贵的产品
- 找出单价最便宜的产品
实战和作业
编写程序,创建一个字符串的ArrayList,要求如下
添加如下String类型的数据:“张三”,“李四”,“王五”,“张三”,”赵六”
判断这个集合是否为空,并打印判断的结果
打印这个集合的大小
判断这个集合是否包含数据"王五"
将”张三”这条数据删掉
输出集合中的每个元素
【扩展】编写程序,进行产品的分类汇总,要求如下
定义一个产品信息列表,存放多个产品信息,单个产品信息包括产品编号、产品名称、产品类别(包括如手机、电脑、食品、医药、鞋包、百货等)、产品价格、产品数量
分别汇总不同产品类别的总价值(产品价格*产品数量),并按总价值降序输出
如,有如下产品数据
001 小米13 手机 2000 5 002 小米电视 电视 5000 2 003 iPhone13 手机 8000 3 004 格力空调 空调 4500 10 005 海尔电视 电视 3000 3
则,分类汇总结果为
空调 45000 手机 34000 电视 19000
Map系列
概述
Map是Java集合框架中重要的系列接口与类
区别于Collection系列,Map系列中,单个元素是以键:值对形式存储,也称为key:value,即成双成对出现
应用场景
如果经常需要根据学号快速的查询学生信息,可以使用Map,效率更高效,模式如下图

像生活中还公司中工号与人的对应;身份证号与人的对应等
...
Map的特点
- key、value都只能是引用数据类型
- key不允许重复,value可以
- key和value一一对应
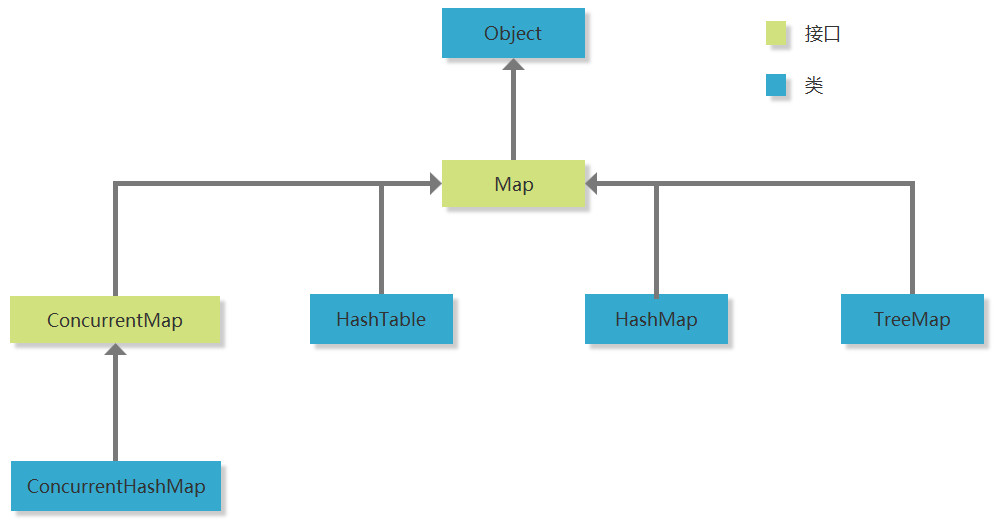
Map关系图谱
常用Map类和接口
- Map接口,Map系列集合的父接口,定义了一系列通用的方法
- ConcurrentMap接口,是一个线程安全的Map接口
- ConcurrentHashMap类,在ConcurrentMap的基础上,使用了HashMap的特点,性能更好
- HashTable类,是一个较早的类,key不允许null值,是线程安全的;与HashMap类似,HashMap系列的类基本能实现HashTable类功能
- HashMap类,无序,key允许有一个null,是非线程安全的,性能更好;是最常用的Map集合类
- TreeMap类,有序,相比HashMap,性能稍差
- ConcurrentMap接口,是一个线程安全的Map接口
HashMap
概述
- 是实际开发中常用的Map集合类
- 在访问效率方面,区别于基于数组和链表的类,HashMap查询、插入、删除的效率都很高
- 特点
- 无序,key不可重复,key可以有一个null
- 只支持引用数据类型
- 底层使用数组,并结合链表、红黑树结构
- 数组,key通过哈希算法计算后,存储到指定的数组位置
- 默认初始容量(initialCapacity)为16,可以在创建对象的时候通过构造方法设置
- 自动扩容,如果使用默认初始容量,会随着元素的增加扩容,载荷因子(loadFactor)默认为0.75;即当数组中使用超过当前容量*0.75个元素时,会自动扩容,扩容为原来容量的2倍
- 链表,不同的key通过哈希算法计算后,如果存储到了相同的位置(哈希冲突),则该位置的存储方式会转换成链表
- 红黑树,当上述链表的元素个数大于8时,会转成效率更高的红黑树结构;红黑树是一个平衡二叉树,查询、插入、删除效率都很好
- 数组,key通过哈希算法计算后,存储到指定的数组位置
- 线程不安全
- 提供了很多便利的操作方法
源码解析【扩展】
哈希表也叫散列表,是一种非常重要的数据结构,应用场景及其丰富,许多缓存技术(比如:Redis)的核心其实就是在内存中维护一张大的哈希表,而HashMap的实现原理也常常出现在各类的面试题中,重要性可见一斑
数据结构的物理存储结构只有两种:顺序存储结构和链式存储结构。而在上面我们提到过,在数组中根据下标查找某个元素,一次定位就可以达到,哈希表利用了这种特性,哈希表的主干就是数组
其中存储的核心代码如下,分别是数组和链表,下面是JDK1.7的源码截图

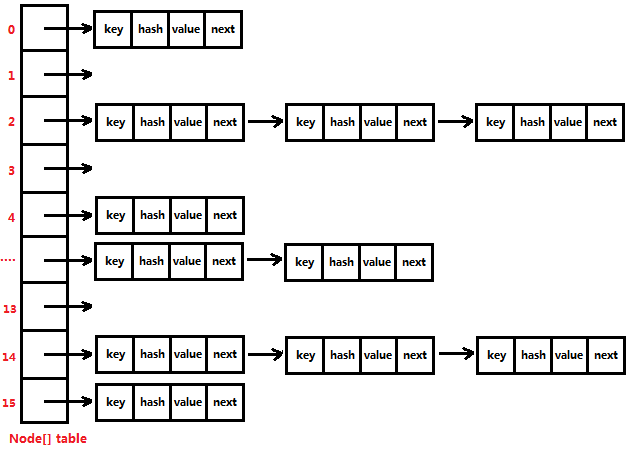
其中的,Node[] table 就是HashMap的核心数组结构,我们也称之为“位桶数组”。我们再继续看Node是什么,源码如下

在Node类中,key存储的是“键对象”,value存储的是“值对象”,hash存储的是“键对象的哈希值”,而next存储的就是“指向下一个节点的地址值”。显然Node类就是一个单链表节点类,我们使用图形表示该单链表如下所示

然后,我们画出Node[]数组的结构(这也是HashMap在JDK1.7的存储结构);并由图可知,在JDK1.7版本中,HashMap底层使用的哈希表就是“数组+链表”来实现,也就是数组存储的每个元素都是一个单链表
存储原理分析
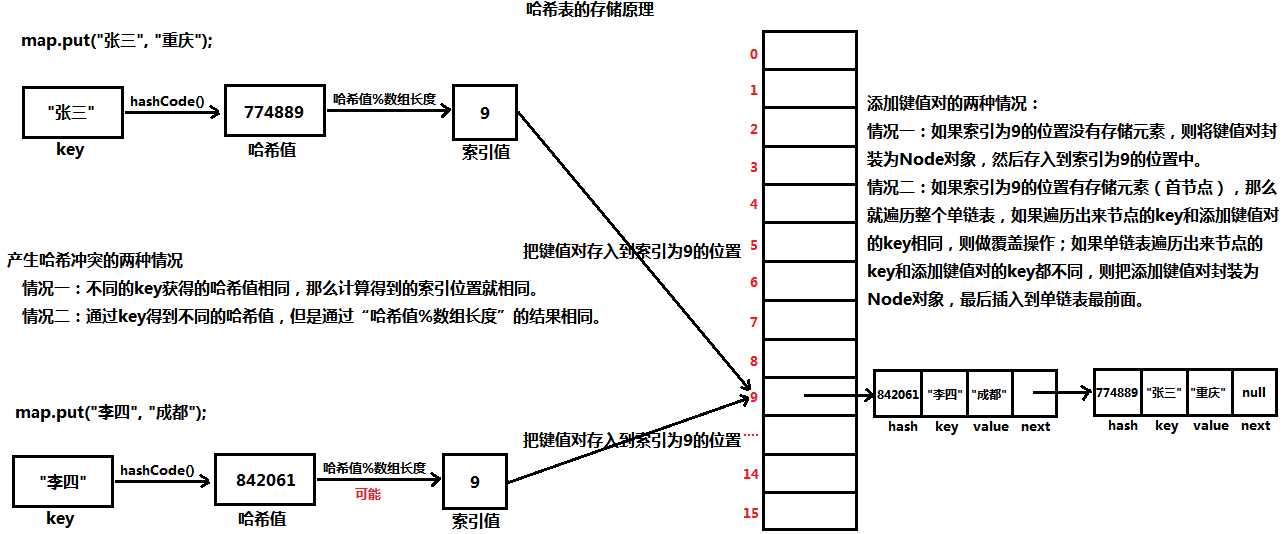
存储原理图如下
散列函数
- 散列函数(也就是hashCode()方法),通过散列函数获得key对象的哈希码,实际上就是建立起key值与int值映射关系的函数。这就好比每个人都有一个身份证号一样,无论是男是女,出生在何处,都可以通过身份证号来分辨,这就是把人的信息映射成一串数字的典型做法。散列函数和此类似,不过是把任意的Java对象,映射成一个int数值(散列均匀,尽量不重复),供哈希表使用
- 另外,通过hashCode()方法获得的结果是一个很大的整数,我们的哈希表不可能提供那么大的存储空间,所以我们还需要对获得的哈希码值做处理。现实开发中,最常见的做法就是“取余法”,把获得的“哈希值 % 数组长度”,这样得到的结果就在[0, 数组长度-1]之间,也就是获得键值对在table数组的存储位置
散列碰撞
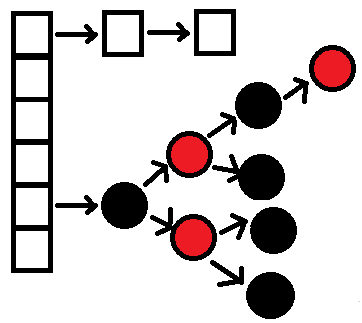
通过hashCode()方法,获得了一个散列均匀的哈希码值,但是不同的key对象获得哈希码值可能相同;另外,通过对不同的“哈希值 % 数组长度”得到的索引值也可能相同,那就意味着在哈希表的某个索引位置需要存储多条数据,这就是所谓的散列碰撞问题。
目前比较通用的解决散列碰撞的方法,可以使用“数组+链表”组合的方式。当出现散列碰撞时,在该位置的数据就通过单链表的方式链接起来,这样一来数组中的每个元素维护的就是一个单链表啦
JDK1.7与JDK1.8的区别
在JDK1.7中,底层table数组在构造方法中初始化,在JDK1.8中,底层table数组在第一次调用put()方法时初始化。
在JDK1.7中,处理哈希冲突采用的是“头插法”;在JDK1.8中,处理哈希冲突采用的是“尾插法”。
在JDK1.7中,HashMap底层采用“数组+链表”来实现;在JDK1.8中,HashMap底层采用“数组+链表+红黑树”来实现。
说明:当单链表的个数大于等于8并且table数组的空间长度大于等于64,则单链表就会变为红黑树;删除红黑树的节点时,如果节点个数小于等于6,则红黑树就变为单链表
底层table数组的长度
通过HashMap集合的无参构造方法来创建集合,则底层table数组的空间长度默认为16

通过HashMap集合的有参构造方法创建集合,则底层table数组肯定为2的整数次幂,也就是空间长度为大于实参的最小2的整数次幂,如下代码所示
public class Test02 {
public static void main(String[] args) {
// 调用构造方法的实参为15,则底层的table数组空间长度为:16
HashMap<String, Integer> hashMap1 = new HashMap<>(15);
// 调用构造方法的实参为1000,则底层的table数组空间长度为:1024
HashMap<String, Integer> hashMap2 = new HashMap<>(1000);
}
}为什么HashMap集合底层table数组的空间长度必须为2的整数次幂呢???把table数组空间长度设置为2的整数次幂,就是为了加快散列计算以及减少散列冲突。
为什么可以加快散列计算?因为& 运算属于位运算,是直接基于二进制做的操作,因此&运算比%运算效率更高。当table数组的空间长度(length)为2的整数次幂,则执行“hash & (length - 1)”和“hash % length”的运算的结果相同,但是&运算的效率高于%运算,所以建议哈希表的容量设置为2的整数次幂,代码验证如下
public class Test01 {
public static void main(String[] args) {
// 获得散列码值,值为:2998638
int hashCode = "ande".hashCode();
// 计算得到2^14的结果,结果为:16384
int length = (int)Math.pow(2, 14);
// &运算结果为:366
System.out.println(hashCode & (length - 1));
// %运算结果为:366
System.out.println(hashCode % length);
}
}为什么可以减少冲突?假设现在table数组空间长度length可能是偶数也可能是奇数。
当length为偶数时,则length-1为奇数,而奇数的二进制最低位肯定为1,这样hash &(length-1) 结果的二进制最低位可能为0,也可能为1(这取决于hash的值)。也就是运算的结果可能为偶数,也可能为奇数,这样便可以保证散列的均匀性。
当length为奇数时,则length-1为偶数,而偶数的二进制最低位肯定为0,这样hash & (length-1)结果的二进制最低位肯定为0。也就是运算的结果肯定为偶数,这样得到的结果对应的就是table数组索引为偶数的位置,那么流浪费了近一半的空间。
因此,table数组空间长度为2的整数次幂,是为了使不同hash值发生碰撞的概率较小,这样就能使元素在哈希表中均匀地散列
设置HashMap初始化容量
- 当哈希表中的元素越来越多的时候,散列碰撞的几率也就越来越高(因为数组的长度是固定的),从而导致单链表过长,降低了哈希表的性能,此时我们就需要对哈希表进行扩容操作。
- 那么HashMap什么时候进行扩容呢?当执行put()操作的时候,如果HashMap中存储元素的个数超过“数组长度* loadFactor”的结果(loadFactor指的是负载因子,loadFactor的默认值一般为0.75),那么就就需要执行数组扩容操作。
- 所谓的扩容操作,就是把数组的空间大小扩大一倍,然后遍历哈希表中元素,把这些元素重新均匀分散到扩容后的哈希表中。例如,默认情况下,数组大小为16,那么当Hashtable中元素个数超过16*0.75=12的时候,就需要执行扩容操作,把数组的大小扩展为2*16=32,然后重新计算每个元素在数组中的位置,这是一个非常消耗性能的操作。
- 为了避免扩容带来的性能损坏,建议使用哈希表之前,先预测哈希表需要存储元素的个数,提前为哈希表中的数组设置合适的存储空间大小,避免去执行扩容的操作,进一步提升哈希表的性能。例如:我们需要存储1000个元素,按照哈希表的容量设置为2的整数次幂的思想,我们设置哈希表的容量为1024更合适。但是0.75*1024 < 1024,需要执行消耗性能的扩容操作,因此我们设置哈希表的容量为2048更加合适,这样既考虑了&的问题,也避免了扩容的问题。
- 思考:当我们创建一个HashMap对象,设置哈希表的容量为15,请问HashMap对象创建成功后,哈希表的实际容量为多少呢??
常用接口
- size方法,Map集合长度
- put方法,往Map集合中添加一个元素,如果key已经存在,则只会更新value
- get方法,根据key获取指定元素的value
- remove方法,删除key的元素
- containsKey方法,是否包含某个key的元素
- containsValue方法,是否包含某个value的元素
- isEmpty方法,Map集合是否为空,即不包含一个元素
- keySet方法,获取所有key列表,返回值类型为Set类型
- values方法,获取所有value列表,返回值类型为Collection类型
- entrySet方法,返回Map集合中的数据Set列表,多用于遍历每一对key:value,返回类型为Set<Map.Entry<kye,value>>
- ...
定义和使用
方式1,泛型方式,常用方式,只支持指定类型的对象
实例代码
//定义,只支持指定类型的数据
Map<Integer,Student> map=new HashMap <>();
//使用
//添加
Student s1 = new Student();
s1.setId(1001);
s1.setName("张三");
map.put(s1.getId(),s1);
Student s2 = new Student();
s2.setId(1002);
s2.setName("李四");
map.put(s2.getId(),s2);
//根据key获取其中某一个元素
map.get(1002);
//根据key删除其中某一个元素
map.remove(1001);//删除
//...其他方法
应用实例
应用实例1,正常使用,使用字符串和包装类;人员工资操作
实例代码
package com.bjpowernode.demo;
import java.util.Collection;
import java.util.HashMap;
import java.util.Map;
import java.util.Set;
/**
* HashMap示例
*/
public class HashMapDemo {
public static void main(String[] args) {
//定义人员工资map
Map <String,Double> map = new HashMap <>();
//使用,添加元素
map.put("张三",12000.8);
map.put("李四",7500.98);
map.put("王小五",3400.0);
map.put("赵大六",6800.88);
//使用,根据key查找元素
Double salary = map.get("李四");
System.out.println("李四的工资:"+salary);
//使用,根据key删除
map.remove("李四");
//使用,重新根据key查找元素
salary = map.get("李四");
System.out.println("李四的工资:"+salary);
//使用,是否包含某个key
System.out.println("HashMap中是否有王小五?"+map.containsKey("王小五"));
//使用,是否包含某个value
System.out.println("HashMap中是否有工资为6800.88的人?"+map.containsValue(6800.88));
//使用,获取所有key列表
Set<String> names = map.keySet();
System.out.println("员工列表:"+names);
//使用,获取所有value列表
Collection <Double> salaries = map.values();
System.out.println("工资列表:"+salaries);
//使用,遍历Map集合
System.out.println("----------员工工资列表----------");
Set<Map.Entry<String,Double>> datas = map.entrySet();
for(Map.Entry<String,Double> item :datas){
System.out.println(item.getKey()+":"+item.getValue());
}
}
}输出结果,运行查看结果
应用实例2,正常使用,使用自定义类型
学生类
package com.bjpowernode.demo;
import java.util.Objects;
/**
* 学生类
*/
public class Student {
private Integer id;
private String name;
private Integer age;
private Float weight;
public Student() {
}
public Student(Integer id, String name, Integer age, Float weight) {
this.id = id;
this.name = name;
this.age = age;
this.weight = weight;
}
public Integer getId() {
return id;
}
public void setId(Integer id) {
this.id = id;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public Integer getAge() {
return age;
}
public void setAge(Integer age) {
this.age = age;
}
public Float getWeight() {
return weight;
}
public void setWeight(Float weight) {
this.weight = weight;
}
/**
* 覆盖toString方法
*
* @return
*/
@Override
public String toString() {
return "[" + this.id + "," + this.getName() + "," + this.getAge() + "," + this.getWeight() + "]";
}
@Override
public boolean equals(Object o) {
if (this == o) return true;
if (o == null || getClass() != o.getClass()) return false;
Student student = (Student) o;
return id.equals(student.id);
}
@Override
public int hashCode() {
return Objects.hash(id);
}
}HashMap实例
package com.bjpowernode.demo;
import java.util.Collection;
import java.util.HashMap;
import java.util.Map;
import java.util.Set;
/**
* 正常使用,使用自定义类型
*/
public class StudentHashMapDemo {
public static void main(String[] args) {
//定义人员工map
Map<Integer, Student> map = new HashMap<>();
//使用,添加元素
Student student = new Student(1, "张三", 33, 75.3f);
map.put(student.getId(), student);
student = new Student(2, "李四", 18, 60.3f);
map.put(student.getId(), student);
student = new Student(3, "王小五", 27, 55.73f);
map.put(student.getId(), student);
student = new Student(4, "赵大六", 47, 78f);
map.put(student.getId(), student);
System.out.println("--------------原始数据--------------");
System.out.println(map);
//使用,根据key查找元素
System.out.println("--------------根据key查找元素(key为2)--------------");
student = map.get(2);
System.out.println("ID为2的学生信息:" + student);
//使用,根据key删除
System.out.println("--------------根据key删除元素(key为2)--------------");
map.remove(2);
System.out.println("删除后的数据为:");
System.out.println(map);
//使用,重新根据key查找元素
System.out.println("--------------重新根据key查找元素(key为2)--------------");
student = map.get(2);
if (student != null) {
System.out.println("ID为2的学生信息:" + student);
} else {
System.out.println("ID为2的学生信息不存在!");
}
//使用,是否包含某个key
System.out.println("--------------是否包含某个key的元素(key为2)--------------");
System.out.println("HashMap中是否有key为2的元素?" + map.containsKey(2));
//使用,是否包含某个value;必须覆盖泛型类型Student中的equals、hashCode方法,明确业务上地相等
System.out.println("--------------是否包含某个value的元素(value为新的学生对象)--------------");
Student value = new Student(1, "张三", 33, 75.3f);
System.out.println("HashMap中是否有value上述对象的元素?" + map.containsValue(value));
//使用,获取所有key列表
System.out.println("--------------获取所有key--------------");
Set<Integer> ids = map.keySet();
System.out.println("学生ID列表:" + ids);
//使用,获取所有value列表
System.out.println("--------------获取所有value--------------");
Collection<Student> students = map.values();
for (Student item : students) {
System.out.println("学生信息:" + item);
}
//使用,遍历Map集合
System.out.println("--------------遍历map--------------");
Set <Map.Entry <Integer, Student>> datas = map.entrySet();
for (Map.Entry <Integer, Student> item : datas) {
System.out.println(item.getKey() + ":" + item.getValue());
}
}
}输出结果,运行查看结果
LinkedHashMap
概述
- LinkedHashMap类继承于HashMap类,在LinkedHashMap类中没有新增任何方法,它的底层采用“哈希表+链表”结构,能够保证元素存与取的顺序完全一致。
- LinkedHashMap集合和HashMap集合用法几乎一模一样。当然,LinkedHashMap集合中的key不能重复,我们需要通过重写hashCode()与equals()方法来保证可以的唯一。另外,key的取值可以为null,并且如果key发生了重复,则做覆盖操作
应用实例
应用实例1,LinkedHashMap使用
public class Test02 {
public static void main(String[] args) {
// 创建一个LinkedHashMap对象
LinkedHashMap<String, Integer> map = new LinkedHashMap<>();
// 添加键值对
map.put("xixi", 11);
map.put("haha", 22);
map.put("hehe", 33);
map.put(null, 44);
// 获得key的迭代器
Iterator<String> iterator = map.keySet().iterator();
while (iterator.hasNext()) {
// 获取key值
String key = iterator.next();
// 输出key和value
System.out.println("key:" + key + "value:" + map.get(key));
}
}
}
HashTable
概述
Hashtable集合和HashMap集合用法几乎一模一样,它的底层依旧采用“哈希表”来存储键值对,具备查询速度快,在很多情况下它们可以互用。
只不过Hashtable类继承于Dictionary类并实现了Map接口,HashMap类只是Map接口的实现类。另外Hashtable的方法添加了Synchronized关键字确保线程同步检查,效率较低。在Hashtable类中,put(K key, V value)方法就增加了synchronized同步标记

相比较于HashMap类,Hashtable类中还包含了许多传统的方法,显然这些方法都不属于集合框架,在Hashtable类中常见的传统方法如下所示

通过Hashtable的keys()和elements()方法,返回的结果是Enumeration接口,此处Enumeration接口功能类似于Iterator接口,都可以实现迭代器的效果,常见的方法如下

应用实例
应用实例1,HashTable使用
public class Test {
public static void main(String[] args) {
// 创建Hashtable对象
Hashtable<String, String> ht = new Hashtable<String, String>();
// 添加键值对
ht.put("cn", "China");
ht.put("jp", "Japan");
ht.put("us", "America");
// 遍历所有的key,keys()方法类似于keySet()方法
Enumeration<String> keys = ht.keys();
while(keys.hasMoreElements()) {
String key = keys.nextElement();
System.out.println(key + "-->" + ht.get(key));
}
// 遍历所有的value,elements()方法类似于values()方法
Enumeration<String> elements = ht.elements();
while(elements.hasMoreElements()) {
String element = elements.nextElement();
System.out.println("value: " + element);
}
}
}
Properties
概述
Java中有个比较重要的类Properties(Java.util.Properties),主要用于读取Java的配置文件,各种语言都有自己所支持的配置文件,配置文件中很多变量是经常改变的,这样做也是为了方便用户,让用户能够脱离程序本身去修改相关的变量设置。
在Java语言中,配置文件常为.properties文件,格式为文本文件,文件的内容的格式是“键=值”的格式,文本注释信息可以用"#"来注释。
Properties类继承自Hashtable类,属于线程安全的类,其特点如下:
- 属于Hashtable的子类,Map集合中的方法都可以用。
- 该Properties集合中没有泛型,键值都是字符串。
- 它是一个可以持久化的属性集,具有和IO流技术相结合的方法。
在Properties集合中,除了能使用Map接口提供的方法,并且在Properties集合还新增了一些方法,常用的方法如下

应用实例
应用实例1,Properties使用
public class Test02 {
public static void main(String[] args) {
// 创建一个Properties对象
Properties properties = new Properties();
// 添加元素
properties.setProperty("张三", "重庆");
properties.setProperty("李四", "成都");
properties.setProperty("王五", "上海");
properties.setProperty("赵六", "北京");
properties.setProperty("王五", "西安"); // 此处会覆盖上海的王五
// 获得所有的key的Set集合
Set<String> set = properties.stringPropertyNames();
// 通过迭代器来遍历Properties集合
Iterator<String> iterator = set.iterator();
while (iterator.hasNext()) {
String key = iterator.next();
String value = properties.getProperty(key);
System.out.println("key:" + key + ",value:" + value);
}
}
}
实战和作业
- 编写程序,创建一个HashMap,要求如下:
- 持续从控制台接收多个人员信息输入,每个人员信息包括姓名(name)和年龄(age),存储到这个HashMap,其中键、值分别为姓名、年龄;直到输入的姓名为end为止
- 判断这个Map集合是否为空,并输出判断的结果
- 输出这个Map集合的大小
- 判断这个Map集合是否包含姓名为“王五”的元素,并输出断结果
- 将map里姓名为”王五”的数据删掉
- 获取map的所有键,并输出
- 获取map的所有值,并输出
- 遍历map的所有健值对,并输出
2、编写程序,使用HashMap,完成本章Collection系列中“实战和作业”第2题产品分类汇总作业