第20章-JVM简介【扩展】
概述
JVM是JRE中运行程序的核心功能
实际应用中,有多种JVM,有的HotSpot、Dalvik和ART(Android)、Microsoft JVM等,可通过java –version查看,现在通常使用的是HotSpot
.java的源代码通过编译成.class字节码后,会通过JVM的类加载器加载进JVM,然后执行,进行数据处理等操作
具体的JVM结构图如下
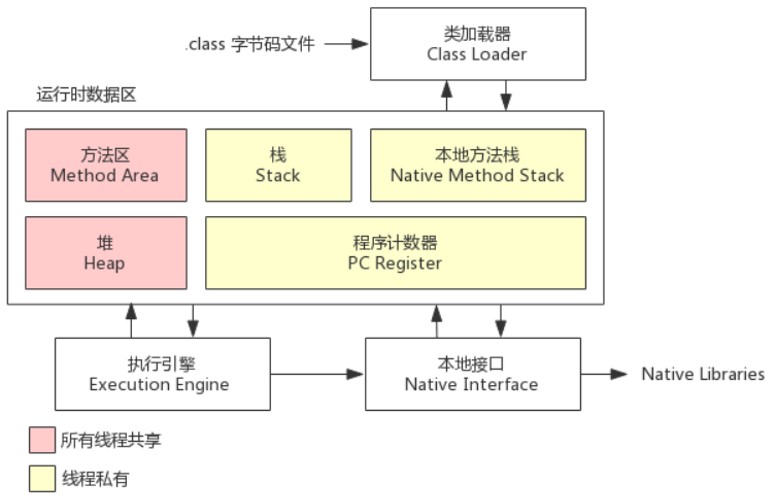
JVM结构图(图片来自网络)
类加载器
类加载器(Class Loader)负责将.class文件的字节码内容加载到内存,并将内容转换成方法区中的运行时数据结构
只负责加载,是否可运行,由执行引擎决定
类加载器按加载顺序由高到低分为4种:
- BootstrapClassLoader,根加载器,虚拟机自带的加载器,用于加载$JAVA_HOME/jre/lib/rt.jar包内的class文件,rt.jar是Java基础类库,包含Java运行环境所需的基础类,由C++实现
- ExtClassLoader ,扩展类加载器,虚拟机自带的加载器,用于加载$JAVA_HOME/jre/lib/ext/**.jar目录下的class文件
- AppClassLoader ,应用程序类加载器,虚拟机自带的加载器,用于加载当前应用的classpath的所有类,也就是我们自己写的那些Java代码
- 自定义加载器,可以通过继承Java.lang.ClassLoader抽象类自定义一个类加载器,多用于大型项目的版本冲突处理、热加载、字节码加密
双亲委派机制,保证优先加载基础类库;任何类的加载,都会先委托父类寻找指定的类加载器加载,形成一个链条,只有当链条中的某个类没有找到类加载器,才会让链条中的子层次中去寻找这一层次的类加载器;如此,可避免自定义的Java类会污染JDK自带的基础类库
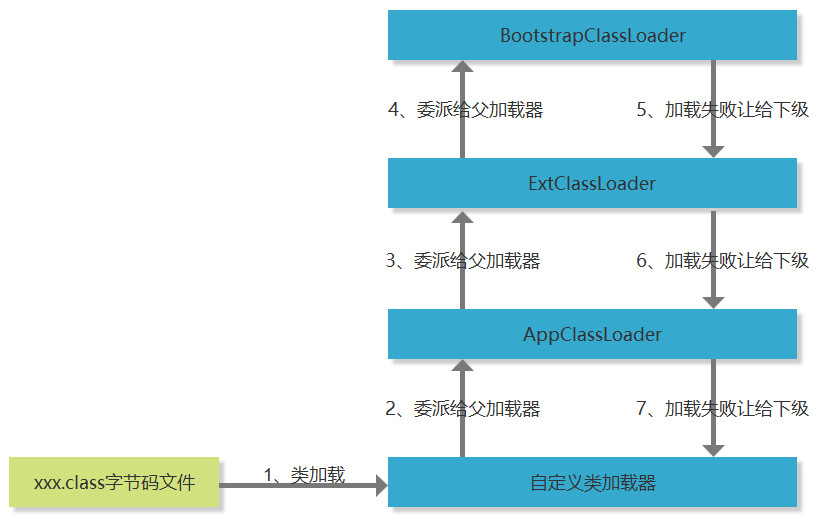
具体加载顺序和过程如下图:
方法区
- 所有线程共享的一个运行时内存区域
- 可以理解为一种规范,不同的JVM实现有不同实现
- 存储了已被虚拟机加载的类型信息、常量、静态变量、即时编译器编译后的代码缓存等
堆
- 一个JVM进程有且只有一个堆,所有线程共享
- 主要包含下面几个部分
- 新生代(Yong Generation),包括一个伊甸园区(Eden Space)和两个幸存者区(Survivor0和Survivor1)
- 老年代(Old Generation)
- 元空间(Meta Space)
- 堆大小可以在启动JVM时通过-Xms、Xmx等参数进行配置
- 垃圾回收机制(Garbage Collection)是针对新生代和老年代的堆内存空间进行回收
- 另外,所有的非基本数据类型对象都活在堆中
栈
- 每个线程会创建一个栈,生命周期与线程一致,属于线程私有
- 主要用于保存局部变量、对象引用、操作数栈、动态链接和返回地址等
- 遵守FILO(First-In/Last-Out)规则,有入栈(Push)和出栈(Pop)操作
- 可在JVM启动时通过-Xss配置容量,超出容量时会抛出StackOverflowError异常
- Linux下的JVM里的栈默认大小一般是1024KB
程序计数器
- 每个线程有一个程序计数器,是线程私有
- 起到一个指针的作用,指向方法区中的方法字节码,存储当前线程的下一条指令地址
- 主要是解决CPU分时在不同的线程间切换,返回线程时,知道从什么地方继续执行
本地方法栈
- 用于管理本地接口的调用
- 主要是Java调用非Java语言代码的接口,非Java接口通过使用native关键字进行标记,并进行调用
本地接口
- 用于融合不同编程语言代码为Java所用,如C/C++
执行引擎
- 解释器(Interpreter):JVM在程序运行时通过解释器逐行将.class字节码转为本地机器指令执行
- 优点:程序启动就可以马上逐行翻译执行
- 缺点:高频代码每次都逐行翻译执行,效率不高
- JIT编译器(Just In Time Compiler,即时编译器):将高频代码直接编译为机器指令然后缓存在方法区中,然后再执行
- 优点:机指令执行效率高
- 缺点:首次将代码编译成本地机器指令时需要耗费一些时间
- JVM在执行Java程序时将解释和编译结合起来,提高运行效率
- 通常,JVM通过以下方式来确实是否为高频代码,这两个的阀值可以配置
- 方法调用计数器:统计方法调用的次数
- 回边计数器:统计循环体执行的循环次数
- 另外,也可以通过配置,让JVM完全解释执行程序或完全编译执行程序
垃圾回收机制
由来
- 在传统的C++等更底层的语言中,对象存储是需要在程序中进行内存空间分配与回收的,如使用malloc、free;如果忘记释放占用的内存空间或内存空间占用过多,会导致程序奔溃乃至系统宕机
- Java语言诞生后,取得了广泛应用,其中重要的特点,就是开发人员不再需要频繁处理对象存储时内存空间的分配与回收
为什么要需要垃圾回收?
- JVM程序所有的引用类型的对象实例与数据,都需要在堆中进行分配,有些甚至需要连续的空间,比如数组
- 如果不进行干预,程序持续的运行,将会耗尽堆空间,产生OutOfMemoryError异常
- 此时,就需要一套机制来保证堆空间得到合理的分配与使用,让程序持续运行
概述
- 程序中的大多对象,在创建后很快就不再使用了,98%以上的对象都是"朝生夕死",这些对象的空间应该及时释放,并加以利用
- JVM通过对堆进行分代,同时针对不同分代使用不同的垃圾回收策略,来保证垃圾回收的效率和堆空间的合理使用
- 垃圾回收机制是JVM负责自动运行的,程序并不能通过代码直接控制,虽然有System.gc()方法来进行Full GC(Minor GC + Major GC),但并不能确定什么时候能真正进行回收
如何进行垃圾回收?
第一步,确定算法,标记垃圾
如何标记垃圾?需要使用垃圾标记的算法,使用的是“可达性分析算法”
其算法思路是,以根(GC Roots)为起点,从上到下搜索被根对象连接的目标是否可达,可达即为存活对象,不可达则为垃圾;如下图示例
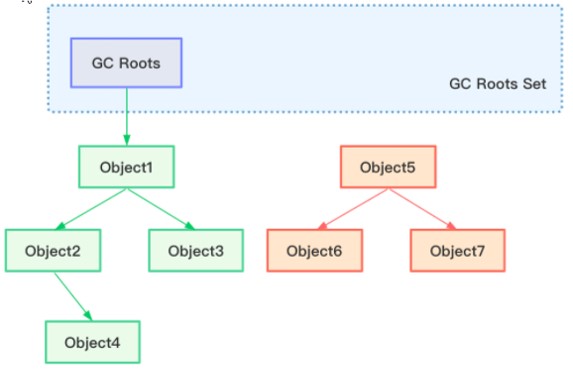
GC Roots(图片来自网络) 根(GC Roots)的主要类别有:
- 虚拟机栈中引用的对象
- 本地方法栈内引用的对象
- 方法区中类静态属性引用的对象,如Java类的引用类型静态变量
- 方法区中常量引用的对象
- 所有被synchronized持有的对象
- Java虚拟机内部引用
- 反映Java虚拟机内部情况的JMXBean、JVMTI中注册的回调、本地代码缓存等
第二步,使用算法,分代收集
其具体步骤如下,可参考示意图理解:
所有对象创建都放到伊甸园区
伊甸园区满后,触发Minor GC,通过第一步算法标记后,删除未引用对象,将幸存对象复制到幸存者0区,清空伊甸园区
随着对象持续创建伊甸园区再次满后,再次进行Minor GC,通过第一步算法标记后,删除未引用对象,将幸存对象复制到幸存者1区;同时,将幸存者0区的对象年龄+1复制到幸存者1区,清空伊甸园区和幸存者0区
随着对象继续持续的创建,伊甸园区又满了后,继续进行Minor GC,通过第一步算法标记后,删除未引用对象,将幸存对象复制到幸存者0区;同时,将幸存者1区的对象年龄+1,并复制到幸存者0区,清空伊甸园区和幸存者1区
随着上述步骤不断的进行,并不断的进行Minor GC,两个幸存者区不断交换存储,里面对象的年龄也越来越大,当年龄到达阀值后,数据将会进入养老区
当程序继续持续运行,上面的Minor GC不断进行将数据复制到养老区;然后养老区满了,会触发养老区的Major GC
如果养老区也满了,无法存放程序新创建的对象时,会产生OutOfMemoryError异常
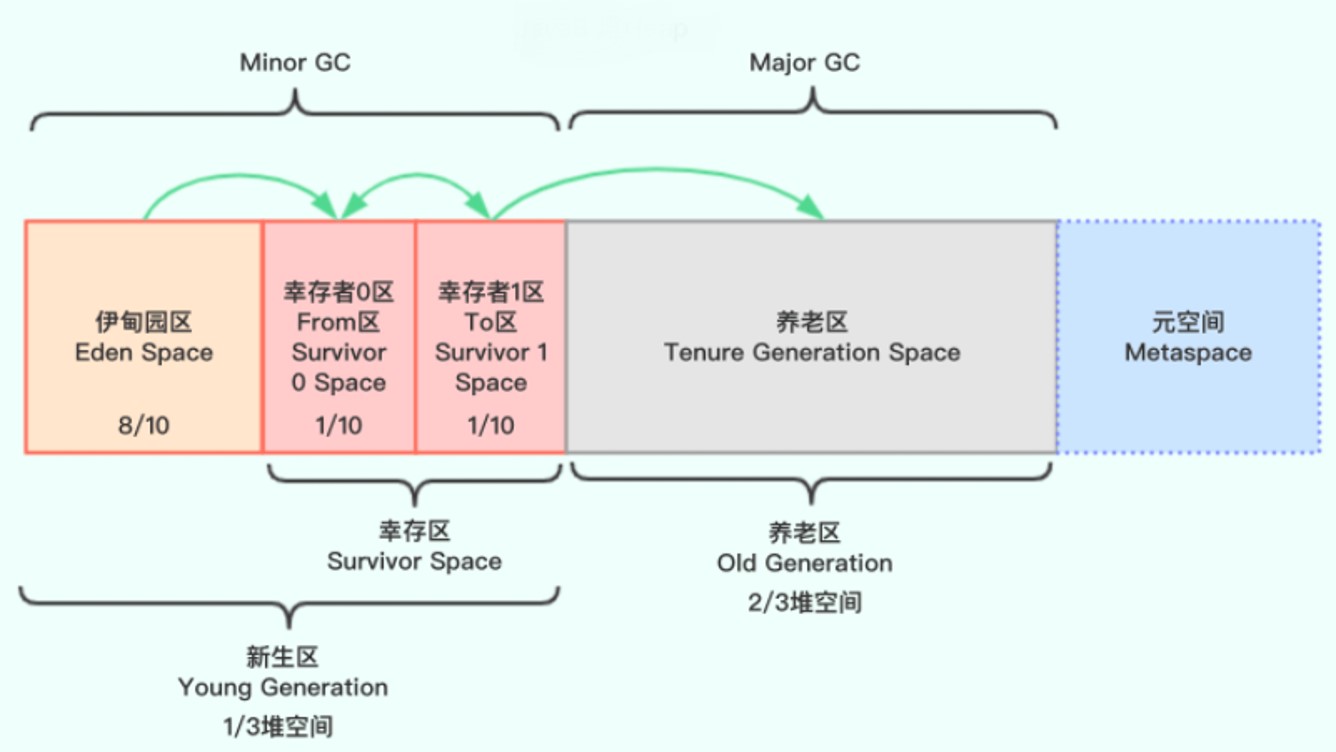
JVM堆中垃圾分代收集示意图(图片来自网络)
查看垃圾回收日志
- 在IDEA中查看:在运行配置的VM options中添加参数-XX:+PrintGCDetails(可以配置后,结合jvisualvm来手动垃圾回收查看输出效果)
- jconsole:使用JDK工具jconsole在本地查看JVM各类参数
- jvisualvm:也是JDK工具,可以查看JVM各类参数,垃圾回收的回收曲线等
- jmap:可以将服务器的java进程的堆空间生成dump进程内存镜像文件,并使用jvisualvm进行分析
注意:不同Java版本,垃圾回收机制并不相同,后续版本还有并行、并发等回收机制,在性能上有提升,可扩展学习
实战和作业
- 熟悉JVM结构,并能大概描述其主要组成部分
- 了解垃圾回收机制的过程