第22章-IO流
文件和目录操作
概述
- 在操作系统中,资源多以文件形式存在,并结合目录进行分类
- 需要进行文件的字节流和字符流的处理,首先要具备操作文件的能力,再进行流处理;文件处理依赖操作系统的能力,使用前,需要打开并占有文件,才进行操作,使用完后,还需要关闭文件
- 文件和目录操作包括创建、删除、判断是否存在等
- Java中主要使用java.io.File类、java.io.Path类负责文件和目录处理
- 同时,java.nio.*包下的一些类也能进行文件和目录的操作
File类常用方法
- exists:文件或目录是否存在
- getPath:获取文件或目录路径
- getAbsolutePath:获取文件或目录的绝对路径
- isDirectory:是否为目录
- createNewFile:创建文件
- delete:删除文件
- mkdir:创建目录
- mkdirs:创建目录,包括目录层次中不存在的父目录
- listFiles:列出当前目录下的所有子文件和目录
- ...
注意
- IO操作如果出现异常,通常会抛出IOException类型异常
- Windows平台使用\作为路径分隔符,Linux平台使用/作为路径分隔符,为了适应不同的平台,最好使用File.separator
应用实例
实例1,目录和文件的常用操作
代码
package com.bjpowernode.demo.file;
import java.io.File;
import java.io.IOException;
import java.nio.file.Path;
import java.nio.file.Paths;
/**
* 文件操作示例
*/
public class FileOperation {
public static void main(String[] args) throws IOException {
//【常用方法】
//文件
File file1 = new File("d:" + File.separator + "temp" + File.separator + "test.txt");
System.out.println("------------------文件操作--------------------");
System.out.println("文件是否存在:" + file1.exists());
System.out.println("文件相对路径:" + file1.getPath());
System.out.println("文件绝对路径:" + file1.getAbsolutePath());
System.out.println("是否为目录:" + file1.isDirectory());
//目录
System.out.println("------------------目录操作--------------------");
File file2 = new File("d:\\temp");
System.out.println("目录是否存在:" + file2.exists());
System.out.println("目录路径:" + file2.getPath());
System.out.println("目录路径:" + file2.getAbsolutePath());
System.out.println("是否为目录:" + file2.isDirectory());
//【文件操作】
//创建文件
System.out.println("------------------创建文件、重命名和删除文件--------------------");
File newFile = new File("d:\\temp\\new_file.txt");
if (newFile.exists() == false) {
boolean result = newFile.createNewFile();
System.out.println("文件创建是否成功?" + result);
}
//文件重命名
File copyFile = new File("d:\\temp\\new_file_copy.txt");
boolean renameResult = newFile.renameTo(copyFile);
System.out.println("文件重命名成功?" + renameResult);
//删除文件
if (newFile.exists()) {
boolean result = newFile.delete();
System.out.println("文件删除是否成功?" + result);
}
//【目录操作】
//创建目录
System.out.println("------------------创建目录--------------------");
File filePath = new File("d:\\temp\\sub_path");
if (filePath.exists() == false) {
boolean result = filePath.mkdirs(); //区别于mkdir,mkdirs会创建目录树中都不存在的目录
System.out.println("目录创建是否成功?" + result);
}
//删除目录
if (filePath.exists() == true) {
//目录存在则可删除
boolean result = filePath.delete();
System.out.println("目录删除是否成功?" + result);
}
//给创建目录下创建文件
newFile = new File("d:\\temp\\sub_path\\a.txt");
if (newFile.exists() == false) {
newFile.createNewFile();
}
newFile = new File("d:\\temp\\sub_path\\b.csv");
if (newFile.exists() == false) {
newFile.createNewFile();
}
//遍历目录文件
System.out.println("------------------遍历目录文件--------------------");
File[] files = filePath.listFiles();
if (files.length > 0) {
for (File item : files) {
System.out.println("文件:" + item.getAbsolutePath());
}
}
//Path处理目录
System.out.println("------------------Path处理目录--------------------");
Path path = Paths.get("d:\\temp\\sub_path");
System.out.println("绝对路径:"+path.toAbsolutePath());
}
}实例2,带过滤器的文件列表
package com.bjpowernode.demo;
import java.io.File;
import java.io.FilenameFilter;
public class FileDemo {
public static void main(String[] args) {
// 创建 File 对象
File file = new File("d:\\temp");
// 获取指定扩展名的文件
File[] list = file.listFiles(new FilenameFilter() {
/**
* 执行过滤操作
* @param dir 指的是需要遍历的file对象
* @param name 遍历出来的文件夹或文件名称
* @return 如果返回true,则保留获得该文件或文件夹
*/
@Override
public boolean accept(File dir, String name) {
return name.endsWith(".java");
}
/**
* 执行过滤操作
* @param pathname 遍历出来的file对象
* @return 如果返回true,则保留获得该文件或文件夹
*/
//@Override
//public boolean accept(File pathname) {
// return pathname.isFile();
//}
});
// 遍历获取到的所有符合条件的文件
for(File f : list) {
System.out.println(f.getName());
}
}
}
【练习】
练习应用实例内容,完成代码编写
编写程序,创建如下图显示的有层次的目录和文件,并输出
- 使用文件操作相关类,创建所有的目录和文件
- 【扩展】使用递归方式列出所有目录和文件

IO流概念
概述
对于任何程序设计语言而言,输入输出(Input/Output)系统都是非常核心的功能。程序运行需要数据,数据的获取往往需要跟外部系统进行通信,外部系统可能是文件、数据库、其它程序、网络、IO设备等等
外部系统比较复杂多变,那么我们有必要通过某种手段进行抽象、屏蔽外部的差异,从而实现更加便捷的编程
输入(Input)指的是:可以让程序从外部系统获得数据(核心含义是“读”,读取外部数据);常见的应用
- 读取硬盘上的文件内容到程序。 a. 例如:播放器打开一个视频文件、word打开一个doc文件。
- 读取网络上某个位置内容到程序。 a. 例如:浏览器中输入网址打开该网址对应的网页内容、下载网络上某个网址的文件。
- 读取数据库系统的数据到程序。
- 读取某些硬件系统数据到程序。 a. 例如:车载电脑读取雷达扫描信息到程序。
输出(Output)指的是:程序输出数据给外部系统从而可以操作外部系统(核心含义是“写”,将数据写出到外部系统);常见的应用:
- 将数据写到硬盘中。 a. 例如:我们编辑完一个word文档后,将内容写到硬盘上进行保存。
- 将数据写到数据库系统中。 a. 例如:我们注册一个网站会员,实际就是后台程序向数据库中写入一条记录。
- 将数据写到某些硬件系统中。
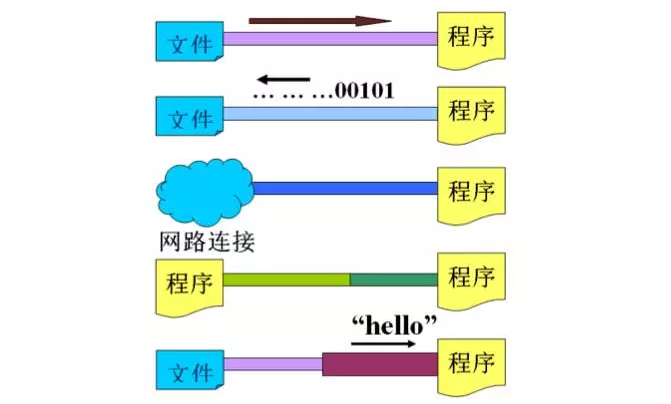
数据源
数据源data source,是提供数据的原始媒介
常见的:数据库、文件、其它程序、内存、网络连接、IO设备等
数据源分为:源设备、目标设备
源设备:为程序提供数据,一般对应输入流
目标设备:程序数据的目的地,一般对应输出流
流概念
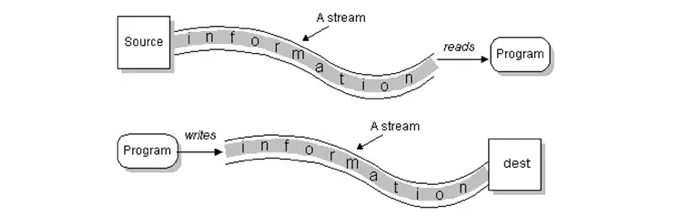
数据源就像水箱,流(stream)就像水管中流着的水流,程序就是我们最终的用户。 流是一个抽象、动态的概念,是一连串连续动态的数据集合
当程序需要读取数据源的数据时,就会通过IO流对象开启一个通向数据源的流,通过这个IO流对象相关方法可以顺序读取流中的数据
分类和体系
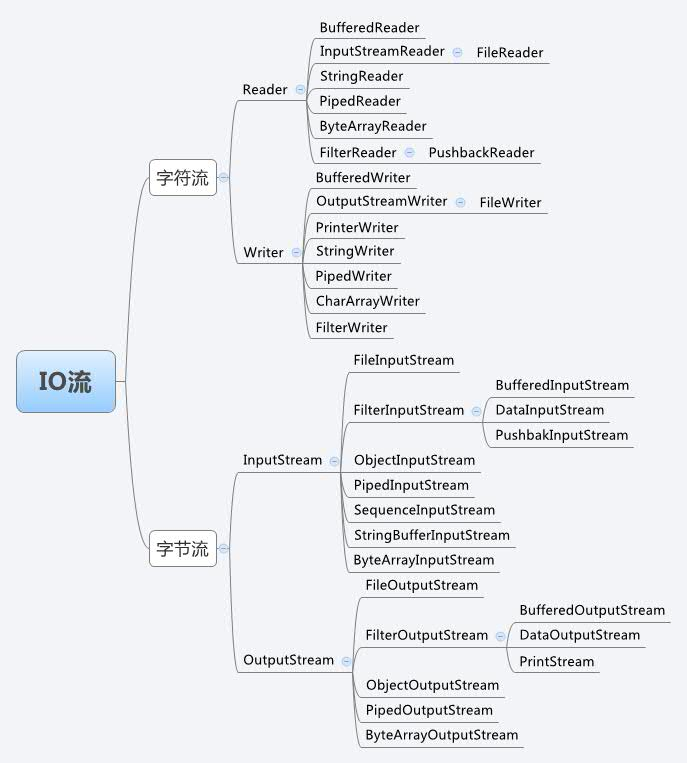
按流的方向分类
- 输入流:数据流向是数据源到程序(InputStream、Reader结尾的流)
- 输出流:数据流向是程序到目的地(OutPutStream、Writer结尾的流)
按处理的数据单元分类
- 字节流:按照字节读取数据(InputStream、OutputStream),命名上以stream结尾的流一般是字节流
- 字符流:按照字符读取数据(Reader、Writer),命名上以Reader/Writer结尾的流一般是字符流
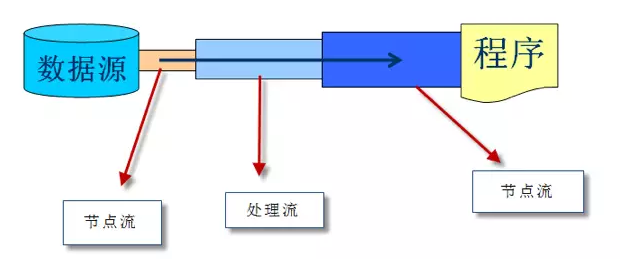
按处理的对象不同分类
- 节点流(普通流):可以直接从数据源或目的地读写数据
- 处理流(包装流):不直接连接到数据源或目的地,是“处理流的流”。通过对其它流进行封装,目的主要是简化操作和提高程序的性能
其中,节点流处于IO操作的第一线,所有操作必须通过他们进行;处理流可以对节点流进行包装,提高性能或提高程序的灵活性;具体如下图
IO流体系
字节流
InputStream
概述
- Java类库中提供的最基础的字节输入流操作类
- 是个抽象类,其中最重要的方法是read(),以字节byte为读取单位,即0-255中的任一值,直到读取末尾返回-1
- 如果读取流时,发生IO错误,则InputStream是不会主动关闭流,一般需要使用try…finally进行处理,在finally中调用close()方法释放我们的输入流资源
- 阻塞,调用read()方法时,一直要等待读取完成,相比一般的程序代码,这个效率更低
- 缓冲,读取数据的时候,如果是一个字节一个字节读取,效率很低,我们也可以通过read(byte[] b)形式一次读取更多内容
主要方法

FileInputStream
概述
- InputSteam类是一个抽象类,是所有“字节输入流”的老祖宗。操作的数据单元为“字节”,该类定义了字节输入流的基本共性功能方法
- 一次性读取文件所有内容,使用FileInputStream类的available()方法,可以获取文件的所有字节个数。但是该方法建议少用,如果遇到文件数据量很大,容易造成内存溢出
主要方法

int read(): 读取一个字节的数据。读取成功,则返回读取的字节对应的正整数;读取失败,则返回-1。
int read(byte[]): 读取一定量的字节数,并存储到字节数组中。读取成功,则返回读取的字节的个数;读取失败,则返回-1。
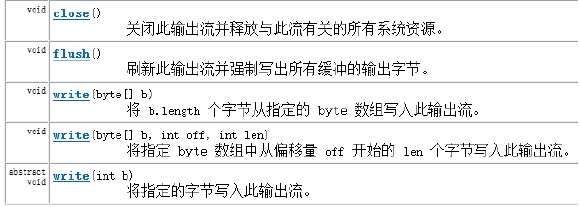
OutputStream
概述
- Java类库中提供的最基础的输出流操作类
- 是个抽象类,其中最重要的方法是write(),以字节byte为单位写入单位,即0-255中的任一值
- 如果写入输出流时,发生IO错误,则OutputStream是不会主动关闭流,一般需要使用try…finally进行处理,在finally中调用close()方法释放我们的输出流资源
- 阻塞,调用write()方法时,一直要等待读取完成,相比一般的程序代码,这个效率更低
- 每次写入一个字节很麻烦,我们可以将要写入的数据转换成byte[]数组,一次性写入输出流
- flush()方法,当我们磁盘文件或网络写入输出流时,操作系统实际上会将输出流放到一个缓存区存起来,等缓存内容达到一定大小时,再写入输出流;flush方法则是强制将当前程序缓存区的内容强制写入输出流
主要方法
FileOutputStream
概述
- FileOutputStream类属于OutputStream抽象类的实现类,在FileOutputStream类中没有新增别的方法,因此该类使用的都是OutputStream抽象类的方法
- FileOutputStream类通过“字节”的方式写出数据到文件,适合所有类型文件(图片文件、视频文件、音乐文件和文本文件等等)
- FileOutputStream类的构造函数中,可以接受一个boolean类型的值,如果参数值为true,就会在文件末位继续添加
主要方法


应用实例
实例1,使用InputStream和OutputStream进行文件读写
代码
package com.bjpowernode.demo;
import java.io.*;
/**
* InputStream和OutputStream示例
*/
public class InputStreamAndOutputStream {
/**
* 入口方法
*
* @param args
* @throws IOException
*/
public static void main(String[] args) {
//文件名
String fileName = "d:" + File.separator + "abc" + File.separator + "bjpowernode" + File.separator + "byte_data.bak";
//【OutputStream】
System.out.println("--------------------写入内容到文件--------------------");
//定义输出字节流引用
OutputStream outputStream = null;
try {
//指向文件输出流对象
outputStream = new FileOutputStream(fileName);
//写入内容的ASCII码值
outputStream.write(98);
//写入内容更复杂
String data = "1a一";
outputStream.write(data.getBytes());
System.out.println("写入成功。");
} catch (IOException ex) {
System.out.println("写入失败,失败信息:" + ex.getMessage());
} finally {
//关闭流
if (outputStream != null) {
try {
outputStream.close();
} catch (IOException e) {
System.out.println("关闭流失败!");
}
}
}
//【InputStream】
System.out.println("--------------------读取文件内容--------------------");
//定义输入字节流引用
InputStream inputStream = null;
try {
//指向文件输入流对象
inputStream = new FileInputStream(fileName);
//定义每次读取字节数
byte[] buffer = new byte[3];
//循环读取
int result;
while ((result = inputStream.read(buffer)) != -1) {
System.out.println("本次读取" + result + "个字节;本次读取的内容是:");
for (int i = 0; i < buffer.length; i++) {
System.out.println(buffer[i]);
}
//以字符串形式输出
System.out.println("以字符串形式输出为:" + new String(buffer));
}
System.out.println("读取成功。");
} catch (IOException ex) {
System.out.println("读取失败,失败信息:" + ex.getMessage());
} finally {
//关闭流
if (inputStream != null) {
try {
inputStream.close();
} catch (IOException e) {
System.out.println("关闭流失败!");
}
}
}
}
}
【练习】
- 练习应用实例内容,完成代码编写
字符流
Reader
概述
- 类似于InputStream,是输入流,但以字符char为读取单位,可以是0~65535之间的任一值
- 如果读取流时,发生IO错误,则Reader是不会主动关闭流,一般需要使用try…finally进行处理,在finally中调用close()方法释放我们的输入流资源
- 阻塞,调用read()方法时,一直要等待读取完成,相比一般的程序代码,这个效率更低
- 缓冲,读取数据的时候,如果是一个字节一个字节读取,效率很低,我们也可以通过read(char[] b)形式一次读取更多内容
主要方法

FileReader
概述
- FileReader类属于Reader抽象类的实现类,在FileReader类中没有新增任何方法
- FileWriter类用于向文件中读取数据,并且每次操作的数据单元为“字符”,属于向文本文件读取字符数据的便捷类
主要方法

Writer
概述
- 类似于OutputStream,是输出流,但以字符char为写入单位,可以是0~65535之间的任一值
- 如果写入流时,发生IO错误,则Writer是不会主动关闭,一般需要使用try…finally进行处理,在finally中调用close()方法释放我们的输入流资源
- 阻塞,调用write()方法时,一直要等待读取完成,相比一般的程序代码,这个效率更低
- flush()方法,与OutputStream类似
主要方法

FileWriter
概述
- FileWriter类属于Writer抽象类的实现类,在FileWriter类中没有新增任何方法。FileWriter类用于向文件文件中存储数据,并且每次操作的数据单元为“字符”,属于向文本文件存储字符数据的便捷类
- 在FileWriter的构造方法中,可以接受一个boolean类型的参数值,如果参数值为true,就会在文件末位继续添加内容
构造方法

应用实例
实例1,使用Reader和Writer进行文件读写
代码
package com.bjpowernode.demo;
import java.io.*;
/**
* 使用Reader和Writer进行文件读写
*/
public class ReaderAndWriter {
public static void main(String[] args) {
//文件名
String fileName = "d:" + File.separator + "abc" + File.separator + "bjpowernode" + File.separator + "char_data.txt";
//【Writer】
System.out.println("-------------------写入内容到文件-------------------");
//定义输出字符流引用
Writer writer = null;
try {
//将引用指向文件字符流对象
writer = new FileWriter(fileName);
//写入内容
writer.write('2');
writer.write('b');
//写入换行
writer.write("\n");
//写入更复杂内容
String data = "1a一";//ASCII码值1:49,a:97
writer.write(data);
System.out.println("写入成功。");
} catch (IOException ex) {
System.out.println("写入失败,失败信息:" + ex.getMessage());
} finally {
//关闭流
if (writer != null) {
try {
writer.close();
} catch (IOException e) {
System.out.println("关闭流失败!");
}
}
}
//【Reader】
System.out.println("-------------------读取文件内容-------------------");
//定义输入字符流引用
Reader reader = null;
//读取文件内容
try {
//将引用指向文件输入字符流对象
reader = new FileReader(fileName);
//每次读取字符数
char[] buffer = new char[3];
//循环读取
int result;
while ((result = reader.read(buffer)) != -1) {
System.out.println("本次读取" + result + "个字符;本次读取的内容是:");
for (int i = 0; i < buffer.length && i < result; i++) {
System.out.println(buffer[i]);
}
}
System.out.println("读取成功。");
} catch (IOException ex) {
System.out.println("读取失败,失败信息:" + ex.getMessage());
} finally {
//关闭流
if (reader != null) {
try {
reader.close();
} catch (IOException e) {
System.out.println("关闭流失败!");
}
}
}
}
}
【练习】
- 练习应用实例内容,完成代码编写
缓冲流
概述
IO流根据功能划分,可分为
- 节点流,可以从或向一个特定的地方(节点)读写数据,例如:FileOutputStream、FileInputStream、FileWriter和FileReader等
- 包装流(处理流),对一个已存在的流的连接和封装,通过所封装的流的提供的方法实现数据读写操作,例如:缓冲流、转换流和对象流等
在我们学习字节流与字符流的时候,大家都进行过读取文件中数据的操作,读取数据量大的文件时,读取的速度会很慢,很影响我们程序的效率,那么我想提高效率,怎么办呢?
那么可以使用缓冲流进行文件读取操作,缓冲流是一个包装流,目的是缓存作用,加快读取和写入数据的速度;主要包括
字节缓冲流:BufferedInputStream、BufferedOutputStream
字符缓冲流:BufferedReader、BufferedWriter
注意:缓冲流属于包装流,只能对已有的流进行封装,不能直接关联文件进行操作
处理原理
- 先把数据写入到缓冲区,等缓冲区存储满了,再把缓冲区的数据写出到文件中或写入到程序中
- 例如:家里盖房子,有一堆砖头要搬在工地100米外,单字节的读取就好比你一个人每次搬一块砖头,从堆砖头的地方搬到工地,这样肯定效率低下。然而聪明的人类会用小推车,每次先搬砖头搬到小车上,再利用小推车运到工地上去,这样你再从小推车上取砖头是不是方便多了呀!这样效率就会大大提高,缓冲流就好比我们的小推车,给数据暂时提供一个可存放的空间
- 通过缓冲流较少了与磁盘的交互次数(操作内存效率高,操作硬盘效率低),因此缓冲流的读取效率高
字节缓冲流
概述
- 字节缓冲流根据流的方向,共有 2 个
- 写入数据到流中,字节缓冲输出流 BufferedOutputStream
- 读取流中的数据,字节缓冲输入流 BufferedInputStream
- 内部都包含了一个缓冲区,通过缓冲区读写,就可以提高了 IO 流的读写速度
BufferedInputStream类
BufferedInputStream类属于InputStream抽象类的实现类,在BufferedInputStream类中没有新增任何方法
可以指定缓冲区的大小,一般情况下,使用默认的缓冲区大小就足够了(默认为8192)
构造方法如下

BufferedOutputStream类
BufferedOutputStream类属于OutputStream抽象类的实现类,在BufferedOutputStream类中没有新增任何方法
可以指定缓冲区的大小,一般情况下,使用默认的缓冲区大小就足够了(默认为8192)
构造方法如下

应用实例
应用实例1,字节缓冲流操作
package com.bjpoernode.demo;
import java.io.*;
/**
* 字节缓冲流操作
*/
public class BufferedStreamDemo {
public static void main(String[] args) {
//输出流,写入文件
BufferedOutputStream bos = null;
try {
// 创建字节缓冲输出流
FileOutputStream fos = new FileOutputStream("d:\\temp\\buffered_byte_stream.data");
bos = new BufferedOutputStream(fos);
// 存数据
bos.write("bjpowernode".getBytes());
} catch (IOException e) {
e.printStackTrace();
} finally {
// 关闭流
if (bos != null) {
try {
bos.close();
} catch (IOException e) {
e.printStackTrace();
}
}
}
//输入流,从文件读取
BufferedInputStream bis = null;
try {
// 创建字节缓冲输入流
FileInputStream fis = new FileInputStream("d:\\temp\\buffered_byte_stream.data");
bis = new BufferedInputStream(fis);
// 读取数据
int len = 0;
byte[] by = new byte[1024];
StringBuilder sb = new StringBuilder();
while ((len = bis.read(by)) != -1) {
sb.append(new String(by, 0, len));
}
System.out.println(sb);
} catch (IOException e) {
e.printStackTrace();
} finally {
// 关闭流
if (bis != null) {
try {
bis.close();
} catch (IOException e) {
e.printStackTrace();
}
}
}
}
}
字符缓冲流
概述
- 为了提高字符流读写的效率,引入了缓冲机制,进行字符批量的读写,提高了单个字符读写的效率。BufferedReader类用于加快读取字符的速度,BufferedWriter类用于加快写入的速度
- 字符缓冲流根据流的方向,共有2个
- 写入数据到流中,字符缓冲输出流BufferedReader
- 读取流中的数据,字符缓冲输入流BufferedWriter
BufferedReader类
BufferedReader类属于Reader抽象类的实现类,在BufferedReader类中新增了readLine()方法
可以指定缓冲区的大小,一般情况下,使用默认的缓冲区大小就足够了(默认为8192)
常用方法如下


读取成功,则返回读取的一行文本内容;读取失败,则返回null
BufferedWriter类
BufferedWriter类属于Writer抽象类的实现类,在BufferedWriter类中新增了newLine()方法
可以指定缓冲区的大小,一般情况下,使用默认的缓冲区大小就足够了(默认为8192)
常用方法如下


newLine()方法会根据当前的操作系统,写入一个换行符
关于flush()方法使用场景
- 假设一个文件有1122个字符,缓冲区大小为100个字符,那么要读取12次,最后一次只有22个字符,但此时缓冲区并没有存满,不能将存储的内容从缓冲区中取出。这时我们需要调用缓冲流自带的一个方法flush(强制写入)将最后一次读取的内容强制写入到文件中去
应用实例
应用实例1,字符缓冲流使用
package com.bjpowernode.demo;
import java.io.*;
/**
* 使用BufferedReader和BufferedWrite进行文件读写
*/
public class BufferedDemo {
public static void main(String[] args) {
//文件名
String fileName = "d:" + File.separator + "abc" + File.separator + "bjpowernode" + File.separator + "buffered_data.txt";
//【BufferedWriter】
System.out.println("-------------------写入内容到文件-------------------");
//定义输出字符流引用
Writer fileWriter = null;
BufferedWriter bufferedWriter = null;
try {
//将引用指向文件字符流对象
fileWriter = new FileWriter(fileName);
bufferedWriter = new BufferedWriter(fileWriter);
bufferedWriter.write("第一行");
bufferedWriter.newLine(); //使用方法换行
bufferedWriter.write("第二行\n"); //使用转义符换行
bufferedWriter.write("第三行");
bufferedWriter.newLine();
bufferedWriter.write("...");
System.out.println("写入成功。");
} catch (IOException ex) {
System.out.println("写入失败,失败信息:" + ex.getMessage());
} finally {
//关闭流
if (bufferedWriter != null) {
try {
bufferedWriter.close();
} catch (IOException e) {
e.printStackTrace();
}
}
}
//【BufferedReader】
System.out.println("-------------------读取文件内容-------------------");
//定义输入字符流引用
Reader fileReader = null;
BufferedReader bufferedReader=null;
//读取文件内容
try {
//将引用指向文件输入字符流对象
fileReader = new FileReader(fileName);
bufferedReader = new BufferedReader(fileReader);
//循环读取
String line;
while ((line = bufferedReader.readLine()) != null) {
System.out.println(line);
}
System.out.println("读取成功。");
} catch (IOException ex) {
System.out.println("读取失败,失败信息:" + ex.getMessage());
} finally {
//关闭流
if(bufferedReader!=null){
try {
bufferedReader.close();
} catch (IOException e) {
e.printStackTrace();
}
}
}
}
}
【练习】
- 练习应用实例内容,完成代码编写
转换流【扩展】
编码带来的问题:在IDEA中,使用FileReader读取硬盘中的文本文件。在Windows系统中,由于IDEA默认采用的都是UTF-8编码,当读取GBK编码格式的文本文件时,就会出现乱码的情况
应用实例,读取GBK(ANSI)编码的文件,将会出现乱码
package com.bjpoernode.demo;
import java.io.FileNotFoundException;
import java.io.FileReader;
import java.io.IOException;
public class MessyCodeDemo {
public static void main(String[] args) {
FileReader reader = null;
try {
// 字符输入流,操作的demo.txt的编码格式为:GBK(属于ANSI)
reader = new FileReader("d:\\temp\\messy.txt");
// 读取文件数据
int read = 0;
while ((read = reader.read()) != -1) {
System.out.print((char)read);
}
} catch (FileNotFoundException e) {
e.printStackTrace();
} catch (IOException e) {
e.printStackTrace();
} finally {
// 关闭流
if (reader != null) {
try {
reader.close();
} catch (IOException e) {
e.printStackTrace();
}
}
}
}
}
概述
Reader和Writer最重要的子类是InputStreamReader和OutputStreamWriter类
- InputStreamReader类包含了一个底层输入流,可以从中读取原始字节,然后再根据指定的编码方式,将这些字节转换为字符并输出
- OutputStreamWriter从运行的程序中接收字符数据,然后使用指定的编码方式将这些字符转换为字节,再将这些字节写入底层输出流中
一般在操作输入或输出内容的时候就需要使用字节流或字符流,但是有些时候需要将字符流变为字节流的形式,或者将字节流变为字符流的形式,所以,就需要另外一组转换流的操作类。转换流本质上就是字符和字节之间的桥梁,转换流原理:字节流+编码表
InputStreamReader是字节流通向字符流的桥梁,OutputStreamWriter是字符流通向字节流的桥梁
如果以文件操作为例,则在内存中的字符数据需要通过OutputStreamWriter变为字节流才能保存在文件之中,读取的时候需要将读入的字节流通过InputStreamReader变为字符流
具体如下图
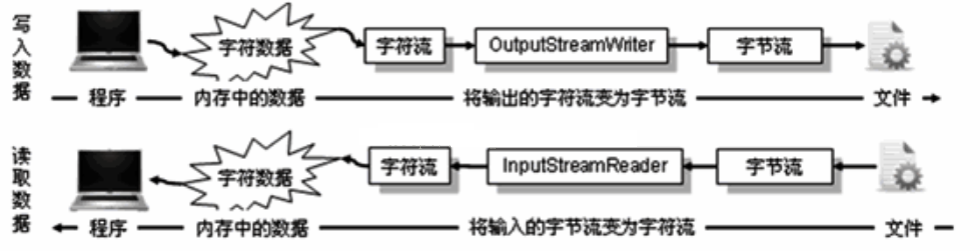
应用场景
- 一旦操作文本涉及到具体的指定编码表时,必须使用转换流
- 源或者目的对应的设备是字节流,但是操作的却是文本数据,可以使用转换流作为桥梁
InputStreamReader类
InputStreamReader属于Reader抽象类的实现类,将输入的字节流变为字符流,即:将一个字节流的输入对象变为字符流的输入对象
指定字符集可以为UTF-8,GBK、Unicode等,我们根据实际情况选用合适的字符集
构造方法如下

OutputStreamWriter类
OutputStreamWriter类属于Writer抽象类的实现类,将输出的字符流变为字节流,即:将一个字符流的输出对象变为字节流的输出对象
指定字符集可以为UTF-8,GBK、Unicode等,我们根据实际情况选用合适的字符集
构造方法如下

应用实例
应用实例1,转换流的使用
package com.bjpoernode.demo;
import java.io.*;
/**
* 转换流使用示例
*/
public class TransformDemo {
public static void main(String[] args) {
//输出流
OutputStreamWriter osw = null;
try {
// 创建字节输出流
FileOutputStream fos = new FileOutputStream("d:\\temp\\transform.txt");
// 创建转换流对象,并指定编码为“GBK”
osw = new OutputStreamWriter(fos, "GBK");
// 存储数据
osw.write("动力节点");
} catch (IOException e) {
e.printStackTrace();
} finally {
// 关闭流:此处只需关闭转换流即可!
if (osw != null) {
try {
osw.close();
} catch (IOException e) {
e.printStackTrace();
}
}
}
//输入流
InputStreamReader isr = null;
try {
// 创建字节输入流(文件编码为:GBK)
FileInputStream fis = new FileInputStream("d:\\temp\\transform.txt");
// 创建转换流对象,编码格式指定为GBK
isr = new InputStreamReader(fis, "GBK");
// 读取数据
char[] buf = new char[1024];
int len = 0;
while ((len = isr.read(buf)) != -1) {
System.out.println(new String(buf, 0, len));
}
} catch (IOException e) {
e.printStackTrace();
} finally {
// 关闭流:此处只需关闭转换流即可!
if (isr != null) {
try {
isr.close();
} catch (IOException e) {
e.printStackTrace();
}
}
}
}
}
FileReader和FileWriter
FileReader并不是Reader的直接子类,而是InputStreamReader的子类;FileWriter也并不直接是Writer的子类,而是OutputStreamWriter的子类
FileWriter和FileReader作为子类,仅作为操作字符文件的便捷类存在
如果操作的字符文件使用的是默认编码表,那么可以不用父类,而直接用子类就完成操作了,简化了代码。但是,如果操作的字符文件使用了其它指定编码时,那么就绝对不能用子类,必须使用字符转换流
具体结构如下图

在下述代码中,三个输入流的在Windows系统中功能是一样的,但是第三个最为便捷
// 创建字节输入流对象
FileInputStream fis = new FileInputStream("d:\\temp\\demo.txt");
// 采用默认编码集
InputStreamReader isr1 = new InputStreamReader(fis);
// 采用指定GBK字符集。
InputStreamReader isr2 = new InputStreamReader(fis, "GBK");
// 采用默认编码集的字符输入流
FileReader fr = new FileReader("d:\\temp\\demo.txt");
【练习】
- 练习应用实例内容,完成代码编写
打印流【扩展】
概述
- 在整个IO包中,打印流是输出信息做方便的类,主要包含字节打印流(PrintStream)和字符打印流(PrintWriter)。打印流提供了非常方便的打印功能,可以打印任何的数据类型,例如:小数、整数、字符串、布尔类型等等
PrintStream类
概述
- 之前在打印信息的时候需要使用OutputStream,但是这样一来,所有的数据输出的时候会非常的麻烦,String——>byte[],但是字节打印流中可以方便的进行输出
- PrintStream类继承于OutputStream类,并且PrintStream类在OutputStream类的基础之上提供了增强的功能,可以方便的输出各种类型的数据(不仅限于byte型)的格式化表示形式。并且,PrintStream类提供的方法从不抛出IOException
- 标准输出流System.out就是PrintStream类型
常用方法
构造方法

常用方法
public void print(Type x),该方法被重载很多次,可以输出任意数据
public void println(Type x),该方法被重载很多次,可以输出任意数据后换行
public void printf(String format,Object...args),格式化输出
应用实例
应用实例1,PrintStream的使用
package com.bjpoernode.demo;
import java.io.FileNotFoundException;
import java.io.PrintStream;
/**
* PrintStream实例
*/
public class PrintStreamDemo {
public static void main(String[] args) throws FileNotFoundException {
// 创建一个字符打印流对象
PrintStream ps = new PrintStream("d:\\temp\\printStream.data");
// 把数组中的元素值输入到文件中
Object[] arr = {true, 123, "bjpowernode", 123.45};
for (int i = 0; i < arr.length; i++) {
// 打印数据
ps.println(arr[i]);
}
ps.close();
}
}应用实例2,格式化输出
package com.bjpoernode.demo;
import java.io.FileNotFoundException;
import java.io.PrintStream;
/**
* PrintStream实例
*/
public class PrintStreamDemo {
public static void main(String[] args) throws FileNotFoundException {
// 创建一个字符打印流对象
PrintStream ps = new PrintStream("d:\\temp\\printStream.data");
// 格式化输出
ps.printf("姓名:%s 年龄:%d 成绩:%f 性别:%c", "小明", 8, 97.5, '男');
ps.close();
// System.out的格式化输出
System.out.printf("姓名:%s 年龄:%d 成绩:%f 性别:%c", "小明", 18, 97.5, '男');
}
}
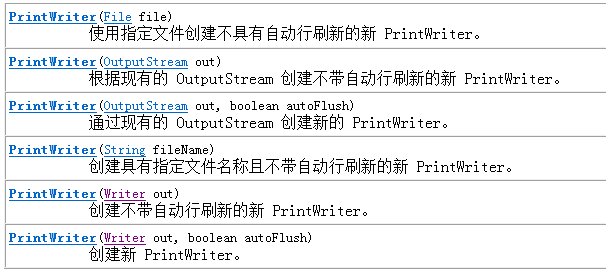
PrintWriter类
概述
- PrintWriter类继承于Writer抽象类,PrintWriter类也提供了PrintStream类的所有打印方法,其方法也从不抛出IOException
- PrintWriter与PrintStream的区别:作为处理流使用时,PrintStream类只能封装OutputStream类型的字节流,而PrintWriter类既可以封装OutputStream类型的字节流,还能够封装Writer类型的字符输出流并增强其功能
常用方法
应用实例
应用实例1,PrintWriter使用
package com.bjpoernode.demo;
import java.io.FileWriter;
import java.io.IOException;
import java.io.PrintWriter;
/**
* PrintWritter实例
*/
public class PrintWriterDemo {
public static void main(String[] args) throws IOException {
FileWriter writer = new FileWriter("d:\\temp\\printWriter.txt");
// 创建字符打印流对象,并设置为自定刷新
PrintWriter pw = new PrintWriter(writer, true);
// 存储数据
for (int i = 0; i < 10; i++) {
pw.println("hello world");
}
pw.close();
}
}
标准输入流&标准输出流
概述
- Java通过系统类System类实现标准输入&输出的功能,定义了3个流变量:in、out和err
- 这三个流在Java中都定义为静态变量,可以直接通过System类进行调用
- System.in,表示标准输入,通常指从键盘输入数据
- System.out,表示标准输出,通常指把数据输出到控制台或者屏幕
- System.err,表示标准错误输出,通常指把数据输出到控制台或者屏幕
标准输入流
使用“System.in”就能获得一个标准的输入流,通过标准的输入流就能够获得用户在控制台中输入的数据
普通的输入流,是获得文件或网络中的数据;而标准的输入流,是获得控制台输入的数据
应用实例
应用实例1,标准输入流使用
package com.bjpoernode.demo;
import java.io.IOException;
import java.io.InputStream;
/**
* System.in实例
*/
public class SystemInDemo {
public static void main(String[] args) throws IOException {
// 获取一个标准的输入流
InputStream in = System.in;
// 读取键盘输入的内容
byte[] by = new byte[1024];
int count = in.read(by);
// 遍历输出读取到的内容
for (int i = 0; i < count; i++) {
System.out.println("-->" + by[i]);
}
}
}
在System类中,还提供了setIn(InputStream in)的静态方法,通过该方法就可以修改输入流,也就是能够修改标准输入流读取的数据源
应用实例
应用实例1,修改输入对象
package com.bjpoernode.demo;
import java.io.FileInputStream;
import java.io.IOException;
import java.io.InputStream;
/**
* System.in实例
*/
public class SystemInDemo {
public static void main(String[] args) throws IOException {
// 修改标准输入流的数据源
System.setIn(new FileInputStream("d:\\temp\\printStream.data"));
// 获取一个标准的输入流
InputStream in = System.in;
// 读取文件中的内容
byte[] by = new byte[1024];
int len = -1;
while ((len = in.read(by)) != -1) {
System.out.print(new String(by, 0, len));
}
}
}
标准的输出流
使用“System.out”就能获得一个标准的输出流,通过标准的输出流就能够把数据在控制台输出
普通的输出流,是把数据写入到文件或网络中;而标准的输出流,是把数据打印在控制台
应用实例
应用实例1,将数据写入到控制台
package com.bjpoernode.demo;
import java.io.PrintStream;
import java.util.Date;
/**
* System.out实例
*/
public class SystemOutDemo {
public static void main(String[] args) {
// 获取一个标准的输出流
PrintStream ps = System.out;
// 在控制台输出数据
ps.println(123);
ps.println(123.456);
ps.println("hello world");
ps.println(true);
ps.println('A');
ps.println(new Date());
}
}应用实例2,将数据定义文件
package com.bjpoernode.demo;
import java.io.FileNotFoundException;
import java.io.FileOutputStream;
import java.io.PrintStream;
import java.util.Date;
/**
* System.out实例
*/
public class SystemOutDemo {
public static void main(String[] args) throws FileNotFoundException {
// 修改标准输出流
System.setOut(new PrintStream(new FileOutputStream("d:\\temp\\system.out.txt")));
// 把数据在文件中存储
System.out.println(123);
System.out.println(123.456);
System.out.println("hello world");
System.out.println(true);
System.out.println('A');
System.out.println(new Date());
}
}
【练习】
- 练习应用实例内容,完成代码编写
数据流
概述
- 通过打印流我们可以将任意数据类型的数据写入到文件中,但是打印流只有输出流,没有输入流,也就是只能存不能取
- 另外,我们通过对源码进行分析,发现打印流最终写入文件的数据类型都为字符串类型。也就是说,我们通过打印流存储的int、double、char、boolean、String和引用数据类型等数据,最后写入文件的类型都是字符串类型
- 那么有没有一种IO流,既能够实现基本数据类型和String类型(暂时不考虑别的引用数据类型)的存取操作,又能实现存、取数据类型的一致性呢?答案就是:数据流
- 数据流将“基本数据类型与字符串类型”作为数据源,以DataInputStream和DataOutputStream来操作基本数据类型和字符串类型数据
- 注意:数据流只有字节流,没有字符流
DataInputStream类
- 使用DataInputStream读取文件的二进制数据,必须通过DataOutputStream来写入,并且写入的顺序必须和读取的顺序相同
- 常见的方法有:readByte()、readShort()、readInt()、readLong()、readFloat()、readDouble()、readChar()、readBoolean()、readUTF()等方法
DataOutputStream类
- 使用DataOutputStream写入文件的二进制数据,必须通过DataInputStream来读取,并且读取的顺序必须和写入的顺序相同
- 常见的方法有:writeByte()、writeShort()、writeInt()、writeLong()、writeFloat()、writeDouble()、writeChar()、writeBoolean()、writeUTF()等方法
应用实例
应用实例1,数据流使用
package com.bjpoernode.demo;
import java.io.*;
/**
* 数据流实例
*/
public class DataStreamDemo {
public static void main(String[] args) {
//输出流
DataOutputStream dos = null;
try {
// 字节输出流
FileOutputStream fos = new FileOutputStream("d:\\temp\\dataStream.data");
// 缓冲流
BufferedOutputStream bos = new BufferedOutputStream(fos);
// 数据输出流
dos = new DataOutputStream(bos);
// 数据输出
dos.writeInt(123); // 写入int类型数据
dos.writeDouble(123.45); // 写入Double类型数据
dos.writeBoolean(false); // 写入Boolean类型数据
dos.writeUTF("bjpowernode"); // 写入String类型数据
} catch (FileNotFoundException e) {
e.printStackTrace();
} catch (IOException e) {
e.printStackTrace();
} finally {
if (dos != null) {
// 关闭流
try {
dos.close();
} catch (IOException e) {
e.printStackTrace();
}
}
}
//输入流
DataInputStream dis = null;
try {
// 字节输入流
FileInputStream fos = new FileInputStream("d:\\temp\\dataStream.data");
// 缓冲流
BufferedInputStream bos = new BufferedInputStream(fos);
// 数据输入流
dis = new DataInputStream(bos);
// 读取数据,需要保证存取顺序一致
int i = dis.readInt();
double d = dis.readDouble();
boolean b = dis.readBoolean();
String str = dis.readUTF();
System.out.println(i + " " + d + " " + b + " " + str);
} catch (FileNotFoundException e) {
e.printStackTrace();
} catch (IOException e) {
e.printStackTrace();
} finally {
if (dis != null) {
try {
dis.close();
} catch (IOException e) {
e.printStackTrace();
}
}
}
}
}注意:要用DataInputStream读取文件,这个文件必须是由DataOutputStream 写出的,否则会抛出EOFException异常,因为DataOutputStream 在写出的时候会做一些特殊标记,只有DataInputStream 才能成功的读取
【练习】
- 练习应用实例内容,完成代码编写
对象流
概述
前面学到的数据流只能实现对基本数据类型和字符串类型的读写,并不能读取对象(字符串除外),如果要对某个对象进行读写操作,我们需要学习一对新的处理流:ObjectInputStream和ObjectOutputStream。
- ObjectOutputStream代表对象输出流,可以对基本数据类型和对象进行序列化操作。
- ObjectInputStream代表对象输入流,可以对ObjectOutputStream写入的基本数据类型和对象进行反序列化
应用实例
应用实例1,使用对象流
package com.bjpoernode.demo;
import java.io.*;
/**
* 数据流实例
*/
public class OjbectStreamDemo {
public static void main(String[] args) {
//输出流
ObjectOutputStream dos = null;
try {
// 字节输出流
FileOutputStream fos = new FileOutputStream("d:\\temp\\objectStream.data");
// 缓冲流
BufferedOutputStream bos = new BufferedOutputStream(fos);
// 数据输出流
dos = new ObjectOutputStream(bos);
// 数据输出
dos.writeInt(123); // 写入int类型数据
dos.writeDouble(123.45); // 写入Double类型数据
dos.writeBoolean(false); // 写入Boolean类型数据
dos.writeUTF("bjpowernode"); // 写入String类型数据
} catch (FileNotFoundException e) {
e.printStackTrace();
} catch (IOException e) {
e.printStackTrace();
} finally {
if (dos != null) {
// 关闭流
try {
dos.close();
} catch (IOException e) {
e.printStackTrace();
}
}
}
//输入流
ObjectInputStream dis = null;
try {
// 字节输入流
FileInputStream fos = new FileInputStream("d:\\temp\\objectStream.data");
// 缓冲流
BufferedInputStream bos = new BufferedInputStream(fos);
// 数据输入流
dis = new ObjectInputStream(bos);
// 读取数据,需要保证存取顺序一致
int i = dis.readInt();
double d = dis.readDouble();
boolean b = dis.readBoolean();
String str = dis.readUTF();
System.out.println(i + " " + d + " " + b + " " + str);
} catch (FileNotFoundException e) {
e.printStackTrace();
} catch (IOException e) {
e.printStackTrace();
} finally {
if (dis != null) {
try {
dis.close();
} catch (IOException e) {
e.printStackTrace();
}
}
}
}
}
序列化和反序列化
概述
- 序列化本质是将程序支持的对象、数组等结构化的内存数据转换为byte[]数组,然后将byte[]数据输出到输出媒介的过程
- 反之,反序列化则是将从输入媒介读取到的byte[]数组还原成程序支持的对象、数组等结构化的内存数据的过程
- Java应用中,需要序列化和反序列化的对象所在的类必须是实现java.io.Serializable接口的
- 一般会进行序列化是都是各类普通的实体类,如JavaBean、POJO、Entity、DTO等
- transient:此关键字修饰的实体类属性,该类的对象不会序列化此属性,比如密码
- 序列化与反序列化在开发过程中应用广泛,主要应用是将对象、列表数据存储到磁盘、暂存于缓存、通过网络传输给其他的应用或程序
- 相比示例,后续在Spring和Spring Boot学习中还有更简单的将对象JSON化格式序列化的方法
应用实例
实例1,序列化与反序列化数据
学生类,注意对比实现Serializable与不实现的效果
package com.bjpowernode.demo;
import java.io.Serial;
import java.io.Serializable;
/**
* 学生类,实体类
* 需要实现Serializable接口,【可尝试不实现此接口效果】
*/
public class Student implements Serializable {
// private static final long serialVersionUID = 7410309765859252062L;
private Integer id;
private String name;
//不做序列化的字段
private transient String password;
public Student() {
}
public Student(Integer id, String name, String password) {
this.id = id;
this.name = name;
this.password = password;
}
public Integer getId() {
return id;
}
public void setId(Integer id) {
this.id = id;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public String getPassword() {
return password;
}
public void setPassword(String password) {
this.password = password;
}
@Override
public String toString() {
return "Student{" + "id=" + id + ", name='" + name + '\'' + ", password='" + password + '\'' + '}';
}
}实例代码
package com.bjpowernode.demo;
import java.io.*;
import java.util.ArrayList;
import java.util.List;
/**
* 序列化和反序列化示例
*/
public class SerializableDemo {
/**
* 入口方法
*
* @param args
*/
public static void main(String[] args) {
//文件名
String fileName = "d:" + File.separator + "temp" + File.separator + "student.data";
//【系列化】
System.out.println("--------------【序列化】写入对象到文件--------------");
//定义字节输出流引用
OutputStream outputstream = null;
//定义对象输出流引用
ObjectOutputStream objectOutputStream = null;
try {
//指向文件输出流对象
outputstream = new FileOutputStream(fileName);
//指向对象输出流引用,并使用文件输出流作为对象输出流构造参数
objectOutputStream = new ObjectOutputStream(outputstream);
//生成学生列表数据
List <Student> students = new ArrayList <>();
Student student = new Student(1, "张三", "111111");
students.add(student);
student = new Student(2, "李四", "222222");
students.add(student);
student = new Student(3, "王五", "333333");
students.add(student);
//将学生列表数据序列化到文件
objectOutputStream.writeObject(students);
System.out.println("序列化成功。");
} catch (IOException ex) {
System.out.println("序列化失败,失败信息:" + ex.getMessage());
} finally {
//关闭流
if (objectOutputStream != null) {
try {
objectOutputStream.close();
} catch (IOException e) {
System.out.println("关闭流失败!");
}
}
if (outputstream != null) {
try {
outputstream.close();
} catch (IOException e) {
System.out.println("关闭流失败!");
}
}
}
//【反序列化】
System.out.println("--------------【反序列化】从文件读取内容到对象--------------");
//定义字节输入流引用
InputStream inputStream = null;
//定义对象输入流引用
ObjectInputStream objectInputStream = null;
try {
//指向文件输入流对象
inputStream = new FileInputStream(fileName);
//指向对象输入流对象
objectInputStream = new ObjectInputStream(inputStream);
//从流指向的文件中读取学生列表数据
List <Student> students = (List <Student>) objectInputStream.readObject();
//输出学生列表信息
System.out.println(students);
System.out.println("反序列化成功。");
} catch (IOException ex) {
System.out.println("反序列化失败,失败信息:" + ex.getMessage());
} catch (ClassNotFoundException ex) {
System.out.println("反序列化失败,类型未找到,失败信息:" + ex.getMessage());
} finally {
//关闭流
if (objectInputStream != null) {
try {
objectInputStream.close();
} catch (IOException e) {
System.out.println("关闭流失败!");
}
}
if (inputStream != null) {
try {
inputStream.close();
} catch (IOException e) {
System.out.println("关闭流失败!");
}
}
}
}
}
序列化接口(Serializable )
- 当一个对象要能被序列化,这个对象所属的类必须实现java.io.Serializable 接口,否则会抛出java.io.NotSerializableException 异常
- 同时当反序列化对象时,如果对象所属的 class 文件在序列化之后进行的修改,那么进行反序列化操作时会抛出 java.io.InvalidClassException异常,发生这个异常的原因是:该类的序列版本号与从流中读取的类描述符的版本号不匹配,核心错误提示如下: java.io.InvalidClassException: com.bjpowernode.object.Student; local class incompatible: stream classdesc serialVersionUID = -5582980675580634268, local class serialVersionUID = 8297661684965222279
- 从错误提示中,我们看到Student对象对应类在序列化时的版本号为:8297661684965222279L,而在反序列化时的版本号为:4913547067458582336L。serialVersionUID 版本号的目的在于验证序列化的对象和对应类是否版本匹配,如果不匹配则抛出java.io.InvalidClassException异常
- 为了避免对象所属的class文件在序列化之后发生修改,从而引发出序列化版本号不一致的问题,我们需要在实现了java.io.Serializable接口之后,通过IDEA手动的添加一个serialVersionUID
瞬态关键字 (transient)
- 当一个类的对象需要被序列化时,某些成员变量无需被序列化,这时不需要序列化的成员变量可以使用关键字transient修饰。只要被transient修饰的成员变量,序列化时这个成员变量就不会被序列化
- 同时static修饰变量也不会被序列化,因为序列化是把对象数据进行持久化存储,而静态的属于类加载时的数据,不会被序列化
【练习】
- 练习应用实例内容,完成代码编写
字节数组流(内存流)【扩展】
概述
- IO流按照处理对象不同来分类,可以分为节点流和包装流。目前我们所学的FileOutputStream、FileInputStream、FileWriter和FileReader都属于节点流,而缓冲流、转换流、打印流、数据流和对象流等都属于包装流。节点流都可以配合包装流来操作,例如直接使用字节流来复制文件效率低,那么我们可以使用缓冲流来提高效率。例如使用字节流来存取任意数据类型数据操作繁琐,那么我们可以使用对象流来简化操作等等
- 接下来,我们要学习的字节数组流,它也属于节点流。字节数组流分为输入流和输出流,分别是:ByteArrayInputStream和ByteArrayOutputStream。使用字节数组流的时候,为了提高效率和简化操作,我们也可以让字节数组流配合包装流来一起使用
- 常见的节点流中,例如:FileInputStreamr和FileReader都是把“文件”当做数据源,而ByteArrayInputStream则是把内存中的“字节数组”当做数据源。字节数组流,就是和内存中的数组相关的一个流,可以将字节数组写到输出流中,也可以将字节数组从输入流中读出来,不涉及磁盘。内存数组输出流可以看成一个可自动扩容的byte数组,可以往里写字节
- 通过字节数组流,我们可以实现所有数据类型(基本数据类型、引用数据类型)和字节数组之间的转换,然后把转换成字节数组后可以保存到文件或者传输到网络
ByteArrayOutputStream类
ByteArrayOutputStream字节数组输出流在内存中创建一个byte数组缓冲区,所有发送到输出流的数据保存在该字节数组缓冲区中。缓冲区初始化时默认32个字节,会随着数据的不断写入而自动增长,但是缓冲区最大容量是2G,只要数据不超过2G,都可以往里写
数据写出完毕后,可使用toByteArray()方法或toString()方法来获取数据,从而实现了将任意数据类型数据转化为字节数组
例如,给一个字节数组,然后往这个数组中放入各种数据,比如整形、布尔型、浮点型、字符串和对象等,这种需求就可以使用ByteArrayOutputStream来实现
应用实例
应用实例1
package com.bjpowernode.demo;
import java.io.BufferedOutputStream;
import java.io.ByteArrayOutputStream;
import java.io.IOException;
import java.io.ObjectOutputStream;
import java.util.Arrays;
import java.util.Date;
/**
* 内存流实例
*/
public class ByteArrayOutputStreamDemo {
public static void main(String[] args) {
try {
//输出流
// 字节数组输出流(节点流),可将任意数据类型转换为字节数组
ByteArrayOutputStream baos = new ByteArrayOutputStream();
// 缓冲流(包装类),用于提高效率
BufferedOutputStream bos = new BufferedOutputStream(baos);
// 对象流(包装流),实现写出任意数据类型
ObjectOutputStream oos = new ObjectOutputStream(bos);
// 使用对象流来写数据
oos.writeInt(123);
oos.writeDouble(123.45);
oos.writeChar('A');
oos.writeBoolean(false);
oos.writeUTF("bjpowernode");
oos.writeObject(new Date());
// 刷新流,在获取数据之前一定要先刷新流,因为使用了包装流
oos.flush();
// 获取数据
byte[] bs = baos.toByteArray();
System.out.println(Arrays.toString(bs));
} catch (IOException e) {
e.printStackTrace();
}
}
}
ByteArrayInputStream类
字节数组输入流就是把一个字节数组 byte[] 包装了一下,使其具有流的属性,可顺序读下去,还可标记跳回来继续读,主要的作用就是用来读取字节数组中的数据
同理,关闭ByteArrayInputStream无效,调用close()方法在关闭此流后仍可被调用
应用实例
应用实例1,内存流使用
package com.bjpowernode.demo;
import java.io.BufferedInputStream;
import java.io.ByteArrayInputStream;
import java.io.IOException;
import java.io.ObjectInputStream;
/**
* 内存流实例
*/
public class ByteArrayInputStreamDemo {
public static void main(String[] args) {
try {
// 获取字节数组,返回上个案例中通过字节数组输出流写出的字节数组
byte[] bs = {-84, -19, 0, 5, 119, 28, 0, 0, 0, 123, 64, 94, -36, -52, -52, -52, -52, -51, 0, 65, 0, 0, 11, 98, 106, 112, 111, 119, 101, 114, 110, 111, 100, 101, 115, 114, 0, 14, 106, 97, 118, 97, 46, 117, 116, 105, 108, 46, 68, 97, 116, 101, 104, 106, -127, 1, 75, 89, 116, 25, 3, 0, 0, 120, 112, 119, 8, 0, 0, 1, -118, -95, -127, 78, 111, 120};
// 字节数组输入流(节点流),用于读取字节数组中的数据
ByteArrayInputStream bios = new ByteArrayInputStream(bs);
// 缓冲流(包装类),用于提高效率
BufferedInputStream bis = new BufferedInputStream(bios);
// 对象流(包装流),实现读取指定类型的数据
ObjectInputStream ois = new ObjectInputStream(bis);
// 读取数据
System.out.println(ois.readInt());
System.out.println(ois.readDouble());
System.out.println(ois.readChar());
System.out.println(ois.readBoolean());
System.out.println(ois.readUTF());
System.out.println(ois.readObject());
} catch (IOException e) {
e.printStackTrace();
} catch (ClassNotFoundException e) {
e.printStackTrace();
}
}
}补充,ByteArrayInputStream和ByteArrayOutputStream是字节数组流,那么与之对应的字符数组流则是StringReader和StringWriter。
与字节数组流相比,字符数组流反而用得更少,因为StringBuilder和StringBuffer也能方便的用来存储动态长度的字符,而且大家更熟悉这些类
【练习】
- 练习应用实例内容,完成代码编写
对象克隆(clone)【扩展】
概述
- 浅拷贝:如果拷贝对象的成员变量是基本数据类型,将复制一份给克隆对象;如果拷贝对象的成员变量是引用数据类型,则将成员变量的地址复制一份给克隆对象,也就是说拷贝对象和克隆对象的成员变量指向相同的存储空间
- 深拷贝:无论拷贝对象的成员变量是引用数据类型还是引用数据类型,都将复制一份给克隆对象,也就是说拷贝对象和克隆对象的引用数据类型成员变量指向的是不同存储空间
浅拷贝的实现
在Object类中,专门提供了clone()的本地方法,通过该方法就能实现对象的“浅拷贝”操作,该方法截图如下

因为Object类提供的clone()方法采用了protected来修饰,也就意味着在所有的Java类中都可以调用该clone()方法。那么,如果某个对象想要实现浅拷贝操作,那么拷贝对象对应的类就重写clone()方法,然后在重写方法中调用super.clone()方法得到需要的拷贝对象
另外,拷贝对象对应的类还必须实现Cloneable接口(该接口中什么内容都没有,仅仅起到标识的作用),否则调用clone()方法时就会抛出CloneNotSupportedException异常
应用实例
应用实例1,实现浅拷贝
狗类,辅助类
package com.bjpowernode.demo;
import java.io.Serializable;
/**
* 狗类
*/
public class Dog {
private String name;
public Dog() {
}
public Dog(String name) {
this.name = name;
}
}老虎类,需要浅拷贝的类
package com.bjpowernode.demo;
/**
* 老虎类
*/
public class Tiger implements Cloneable {
private String name;
private int age;
private Dog dog;
public Tiger() {
}
public Tiger(String name, int age, Dog dog) {
this.name = name;
this.age = age;
this.dog = dog;
}
@Override
protected Object clone() throws CloneNotSupportedException {
return super.clone();
}
@Override
public String toString() {
return "Tiger{" + "name='" + name + '\'' + ", age=" + age + ", dog=" + dog + '}';
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public int getAge() {
return age;
}
public void setAge(int age) {
this.age = age;
}
public Dog getDog() {
return dog;
}
public void setDog(Dog dog) {
this.dog = dog;
}
}浅拷贝实例
package com.bjpowernode.demo;
/**
* 浅拷贝实例
*/
public class ShallowCopyDemo {
public static void main(String[] args) {
try {
// 实例化需要拷贝的对象
Tiger tiger = new Tiger("母老虎", 18, new Dog("哈士奇"));
// 执行对象的拷贝操作(浅拷贝)
Object cloneTiger = tiger.clone();
// 输出:Tiger{name='母老虎', age=18, dog=包名.Dog@5b480cf9}
//【注意,中间的dog对象与下面拷贝的是同一个对象】
System.out.println(tiger);
// 输出:Tiger{name='母老虎', age=18, dog=包名.Dog@5b480cf9}
//【注意,中间的dog对象与上面拷贝的是同一个对象】
System.out.println(cloneTiger);
// 判断两个对象的地址值是否相同,此处输出:false
System.out.println(tiger == cloneTiger);
//【判断里面的dog是否为同一对象,此处输出:true】
System.out.println(tiger.getDog() == ((Tiger) cloneTiger).getDog());
} catch (CloneNotSupportedException e) {
e.printStackTrace();
}
}
}
深拷贝的实现
想要实现“深拷贝”的操作,则拷贝对象对应的类就必须实现Serializable接口,通过序列化和反序列化的操作来完成对象的拷贝,此处为了方便还使用了字节数组流来配合实现
应用实例
应用实例1,深拷贝实现
狗类,辅助类
package com.bjpowernode.demo;
import java.io.Serializable;
/**
* 狗类
*/
public class Dog implements Serializable{
private String name;
public Dog() {
}
public Dog(String name) {
this.name = name;
}
}老虎类,需要深拷贝的类
package com.bjpowernode.demo;
import java.io.Serial;
import java.io.Serializable;
/**
* 老虎类
*/
public class Tiger implements Serializable {
@Serial
private static final long serialVersionUID = 1426112437218885998L;
private String name;
private int age;
private Dog dog;
public Tiger() {
}
public Tiger(String name, int age, Dog dog) {
this.name = name;
this.age = age;
this.dog = dog;
}
@Override
public String toString() {
return "Tiger{" + "name='" + name + '\'' + ", age=" + age + ", dog=" + dog + '}';
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public int getAge() {
return age;
}
public void setAge(int age) {
this.age = age;
}
public Dog getDog() {
return dog;
}
public void setDog(Dog dog) {
this.dog = dog;
}
}深拷贝工具类
package com.bjpowernode.demo;
import java.io.*;
/**
* 深拷贝工具
*/
public class DeepCopyUtil {
/**
* 深拷贝
* @param t 要拷贝的对象
* @return 深拷贝的对象
* @param <T>
* @throws IOException
* @throws ClassNotFoundException
*/
public static <T> T clone(T t) throws IOException, ClassNotFoundException {
//对象转内存流
ByteArrayOutputStream baos = new ByteArrayOutputStream();
ObjectOutputStream oos = new ObjectOutputStream(baos);
oos.writeObject(t);
byte[] bytes = baos.toByteArray();
//内存流转对象
ByteArrayInputStream bais = new ByteArrayInputStream(bytes);
ObjectInputStream ois = new ObjectInputStream(bais);
T result = (T) ois.readObject();
return result;
}
}深拷贝使用
package com.bjpowernode.demo;
import java.io.IOException;
/**
* 深拷贝实例
*/
public class DeepCopyDemo {
public static void main(String[] args) {
try {
// 实例化需要拷贝的对象
Tiger tiger = new Tiger("母老虎", 18, new Dog("哈士奇"));
// 执行对象的拷贝操作(深拷贝)
Object cloneTiger = DeepCopyUtil.clone(tiger);
// 输出:Tiger{name='母老虎', age=18, dog=包名.Dog@7cd84586}
//【注意,中间的dog对象与下面拷贝的不是同一个对象】
System.out.println(tiger);
// 输出:Tiger{name='母老虎', age=18, dog=包名.Dog@5eb5c224}
//【注意,中间的dog对象与上面拷贝的不是同一个对象】
System.out.println(cloneTiger);
// 判断两个对象的地址值是否相同,此处输出:false
System.out.println(tiger == cloneTiger);
//【判断里面的dog是否为同一对象,此处输出:false】
System.out.println(tiger.getDog() == ((Tiger) cloneTiger).getDog());
} catch (IOException e) {
throw new RuntimeException(e);
} catch (ClassNotFoundException e) {
throw new RuntimeException(e);
}
}
}
【练习】
- 练习应用实例内容,完成代码编写
读取配置文件【扩展】
概述
在Java语言中,配置文件为“.properties”后缀的文件,格式为文本文件,文件的内容的格式是“键=值”的格式,文本注释信息可以用"#"来注释;如下面的代码
#用户名
username=admin
#密码
password=123456开发中,我们可以将一些动态数据存入到配置文件中,然后在程序执行的过程中来读取配置文件中的数据,让用户能够脱离程序本身去修改程序相关的一些数据,例如:在反射章节,我们就会读取配置文件中的数据来创建对象
Properties使用
从文件读取配置
在Java语言中,专门提供了Properties集合,在Properties集合中能够存储“键=值”格式的数据,通过Properties集合提供的方法配合IO流就能操作配置文件中的数据
必须指定文件的绝对跨径,或放置在项目根目录
常用方法
方法名 描述 load(Reader reader) 通过字符输入流将配置文件的数据读取到集合中 load(InputStream inStream) 通过字节输入流将配置文件的数据读取到集合中 应用实例
应用实例1,从文件读取配置
config.properties
#用户名
username=admin
#密码
password=123456读取配置
package com.bjpowernode.demo;
import java.io.FileInputStream;
import java.io.IOException;
import java.util.Properties;
/**
* Properties实例
*/
public class PropertiesDemo {
public static void main(String[] args) {
FileInputStream fis = null;
try {
// 创建一个Properties对象
Properties properties = new Properties();
// 创建字节输入流(指向配置文件)
fis = new FileInputStream("config.properties");
// 读取配置文件中的数据
properties.load(fis);
// 根据key获得对应的value值
String userName = properties.getProperty("username");
String password = properties.getProperty("password");
// 输出获得的数据
System.out.println("用户名:" + userName + ",密码:" + password);
} catch (IOException e) {
e.printStackTrace();
} finally {
// 关闭资源
if (fis != null) {
try {
fis.close();
} catch (IOException e) {
e.printStackTrace();
}
}
}
}
}
将配置写入文件
有时也需要动态的将配置写入文件 ,较少使用
常用方法
方法名 描述 store(Writer writer, String s) 通过字符输出流将集合中的数据存入配置文件 store(OutputStream out, String s) 通过字节输出流将集合中的数据存入配置文件 应用实例
应用实例1,将配置写入文件
写入配置
package com.bjpowernode.demo;
import java.io.*;
import java.util.Properties;
/**
* Properties实例
*/
public class PropertiesDemo {
public static void main(String[] args) {
FileOutputStream fos = null;
try {
// 创建一个Properties集合
Properties properties = new Properties();
// 添加键值对
properties.setProperty("username", "jack");
properties.setProperty("password", "123456");
// 创建字节输出流
fos = new FileOutputStream("user.properties");
// 对properties集合进行持久化操作,参数二为对配置文件的描述
properties.store(fos, "data");
} catch (IOException e) {
e.printStackTrace();
} finally {
// 关闭资源
if (fos != null) {
try {
fos.close();
} catch (IOException e) {
e.printStackTrace();
}
}
}
}
}config.properties
#data
#Sun Sep 17 14:09:49 CST 2023
password=123456
username=jack
资源绑定器的使用
在java.util包中,专门提供了一个资源绑定器(ResourceBundle类),用于获取属性配置文件中的内容
使用该方式时,操作的配置文件必须放在src路径中,并且只能绑定xxx.properties文件,绑定配置文件的时候还必须省略后缀.properties
应用实例
应用实例1,使用资源绑定器读取数据
package com.bjpowernode.demo;
import java.util.ResourceBundle;
/**
* ResourceBundle实例
*/
public class ResourceBundleDemo {
public static void main(String[] args) {
// 获得一个资源绑定器,用于绑定config.properties文件
ResourceBundle resourceBundle = ResourceBundle.getBundle("config");
// 获得config.properties配置文件中的数据
String userName = resourceBundle.getString("username");
String password = resourceBundle.getString("password");
// 输出获得的数据
System.out.println("用户名:" + userName + ",密码:" + password);
}
}
【练习】
- 练习应用实例内容,完成代码编写
NIO【扩展】
非阻塞IO(Nonblocking IO),区别于传统的IO,NIO并发性能更好
java.nio.*下也提供了一下NIO的工具类,主要有Channels、Buffers、Selectors等
Netty是一个NIO的开源框架,其并发高、传输快、封装好的特性,被很多框架使用,如Dubbo、RocketMQ、Hadoop、Lettuce等
阻塞式IO与非阻塞式IO对比
阻塞式IO 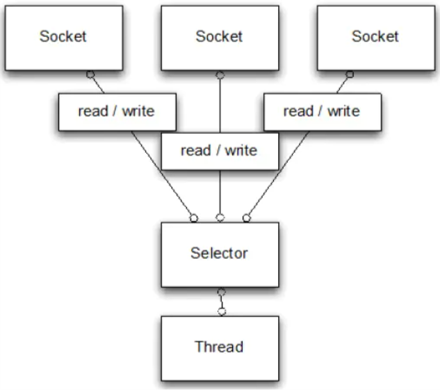
实战和作业
编写程序,完成一段文本的写入和读取,文件名为test.txt,具体要求如下
将下列文件写入文件
大家好,我是动力节点学生xxx
我来自xx省,简称"x"
很高兴认识大家
我技术很牛掰。
读取该文件内容,并将读取的内容按行保存到ArrayList中,遍历输出
编写程序,实现文件拷贝功能;要求能通过使用java命令,实现将一个文件内容拷贝到另外一个文件,如命令java xxx a.txt b.txt,是程序xxx将a.txt内容拷贝到b.txt
编写程序,使用字符流,将九九乘法表写到文件,再读取输出